前言
数据挖掘(Data Mining)是通过自动或半自动化的方式对海量数据进行探索和分析的过程,从其中发掘出有意义或有兴趣的现象,进而归纳出有脉络可循的模型(model),并借以反复印证找出可行的方案。
关联规则介绍
关联规则(association rule)最初是针对购物篮分析(Market Basket Analysis)提出的。假设分店经理想更多的了解顾客的购物习惯,特别是想知道哪些商品可能会在一次购物时同时被购买?为回答该问题,可以通过分析购买数据,发现顾客放入“购物篮”中的不同商品之间的关联,得到顾客的购物习惯。这种关联的发现可以帮助零售商了解哪些商品频繁的被顾客同时购买,从而帮助他们开发更好的营销策略。
在数据挖掘中,关联规则可以被描述为“if前项then后项”的规则。关联规则的目的在于找出数据集中的数据间彼此的关联性。在关联规则的使用中,Apriori算法是最为著名且广泛运用的算法,由Agrawal, Srikant 于1994年首先提出。
关联规则分析的规则是指X→Y,X和Y为对象的集合,X称为前项(antecedents,R称为lhs,即left hand sides),Y称为后项(consequents,R称为rhs,即right hand sides)。我们举以下的Transaction项目列表为例:

以下是几个规则范例:
{Milk, Diaper} => {Beer} (s=0.4, c=0.67)
{Milk, Beer}=>{Diaper} (s=0.4, c=1.0)
{Diaper, Beer}=>{Milk} (s=0.4, c=0.67)
{Beer}=>{Milk, Diaper} (s=0.4, c=0.67)
其中s指支持度support,即物品集X和物品集Y同时出现的概率;c指置信度confidence,指在出现了物品集X的事务T中,物品集Y也同时出现的概率有多大。至于提升lift则反映了“物品集X的出现”对物品集Y的出现概率发生了多大的变化。
R语言实现
下面我们将由R的实际操作,来说明关联规则分析。
以下图beer.xls的数据集为例,若关联规则分析的数据是如下形式,可直接输入到R,1代表有买,0代表没有买,但需先转换成矩阵beer=as.matrix(beer)。

R软件的指令如下:
#加载xlsx包和arules包
library(xlsx)
library(arules)
#从excel文档读取数据集
beer=read.xlsx("d:\\\\beer.xls",header=T,sheetIndex=1)
beer=as.matrix(beer)
#进行关联规则分析,默认参数为是0.1,0.8,10
rule=apriori(beer,parameter=list(supp=0.2,conf=0.8,maxlen=5))
#按support排列取前十的结果
inspect(head(sort(rule,by="support"),10))
结果如下:
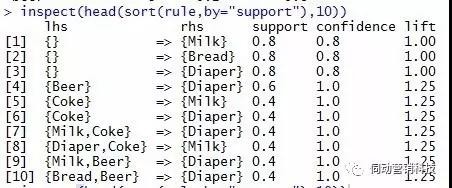
我们还可以在此基础上根据需求,按照confidence或lift排序;或将结果集输入到数据框中调整格式,以便进行进一步的分析或自动化操作。
STORM | 关于我们
伺动营销科技为大中华区领先的 CRM 营销顾问谘询谘询策划与运营服务商,拥有 近20年的专业实战经验,为品牌量身打造精准且聚焦的在地化专业产品与服务。包含企业 CRM 策略规划、CRM策划运营、消费者行为分析服务、O2O 整合性 CRM 解决方案、一物一码解决方案以及 CRM 营销自动化资讯系统等。启动及运营包括 L’Oreal 莱雅集团(Lancôme、Kiehl’s、HR、Biotherm、VICHY等品牌), P&G 集团(安娜苏ANNA SUI、SKII、Oral B等品牌),Pola集团(茱莉蔻Jurlique、H2O等品牌)、统一集团(小茗同学、茶饮事业部) ,雀巢(能恩), 恒天然集团(丰力富、安怡、芝士乐), LVMH集团(Guerlain),爱茉莉太平洋集团(Sulwhasoo), 潮宏基CHJ珠宝, Elizabeth Arden, Clarins, Chanel化妆品等CRM或数据服务。【上海:86-21-61201830/台北:886-2-2740-3886】
版权声明:CosMeDna所有作品(图文、音视频)均由用户自行上传分享,仅供网友学习交流。若您的权利被侵害,请联系删除!
本文链接://www.cosmedna.com/article/378538229.html