我主要阐述了基于Tensorflow的Faster RCNN在Windows上的一个Demo程序,其中,分为两个部分,一个是训练数据导入部分,一个是网络架构部分开始。源程序git地址我会放在文章最后,下载后可以参考对应看一下。
一、程序运行环境说明
首先,我想阐述一堆巨坑,下面只要有一条没有环境或条件达到或做到,你的程序将无法运行:
Windows10 家庭版:
Python3.5+Windows+Visual Studio 2015+cuda9.1
这里,本人踩过几个坑,忘后来人应用这个版本的Demo不要再走:
① Python3.6无法编译该程序。因为作者编译时环境为3.5
② 如果你的电脑是Windows家庭版,不要用Anaconda进行安装Python3.5,直接装上Python3.5即可,因为家庭版的Windows10系统无法安装Anaconda3+Python3.5的环境,Anaconda3默认3.6版或2.7版。
③ 除Visual Studio2015外的版本将无法执行符合要求的编译Python所需的C++环境。(不要问我为什么,我也不知道)
Windows10 企业版:
Anaconda3+Python3.5+Cuda9.1
① Anaconda与Python对应的版本可以百度搜索清华Python镜像中下载。
② 如果用Anaconda搭载python3.5将不需要Visual Studio环境,无需安装。反之,如果没有用Anaconda搭载python,而是直接安装python,就必须要安装Visual Studio 2015的环境。
好了,坑到此结束,说完这些,按照ReadMe编译程序之后,应该程序可以运行了。
我的IDE用的是Pycharm Jetbrain。
二、训练数据导入部分
那么,我们先来看数据导入的环节:
由于物体检测是回归和分类任务,那么导入的数据就要包括物体的位置以及他的类别,那么在程序中,这些信息的根目录在:
...\\FasterRcnn\\Faster-RCNN-TensorFlow-Python3.5-master\\data\\VOCDevkit2007\\VOC2007\\Annotations
图像信息由xml文件读取。
而图像与图像信息xml文件是一一对应的,这些训练集中图像的根目录在:
...\\Desktop\\FasterRcnn\\Faster-RCNN-TensorFlow-Python3.5-master\\data\\VOCDevkit2007\\VOC2007\\JPEGImages
现在,我们回到代码train.py:
可以明显的发现,train文件中主函数中一共就有两句话:
\ntrain = Train()\ntrain.train()\n
第一句就是我们网络训练数据集导入的过程,而第二句主要就是真正的训练数据集的过程,那么我们还是从第一句开始:
首先,我们跳入这句Train(),再跳入VGG16.py中的初始化过程,具体在network.py中:
\nself._feat_stride = [16, ]\nself._feat_compress = [1. / 16., ]\nself._batch_size = batch_size\nself._predictions = {}\nself._losses = {}\nself._anchor_targets = {}\nself._proposal_targets = {}\nself._layers = {}\nself._act_summaries = []\nself._score_summaries = {}\nself._train_summaries = []\nself._event_summaries = {}\nself._variables_to_fix = {}\n
一开始包括了一些参数的指定,例如feat_stride,为后续说到的锚点和原始图像对应的区域。
我们回到train.py接下去看:
self.imdb, self.roidb = combined_roidb("voc_2007_trainval")\n
这一句,把训练的图像信息全部读入到了roidb这样一个变量中,跳入combined_roidb():
\ndef get_roidb(imdb_name):\nimdb = get_imdb(imdb_name)\nprint('Loaded dataset `{:s}` for training'.format(imdb.name))\nimdb.set_proposal_method("gt")\nprint('Set proposal method: {:s}'.format("gt"))\nroidb = get_training_roidb(imdb)\nreturn roidb\n
以上代码,表示了通过名字把roidb读入进来的过程,最后返回了roidb这个变量:
注意到,代码中有这样一句:
roidbs = [get_roidb(s) for s in imdb_names.split('+')]\n
这句的意思就是数据源可能是从多个源头进行导入的,所以假如真的是从多个数据源进行导入,则用加号把各种数据集连起来,到了用到的时候再用split函数把各种数据集的名字分开。
但事实上,程序中只用到了一个数据集,所以下一句是:
roidb = roidbs[0]\n
由于程序确定只有一个数据集的数据,所以只需要取0位置上的数据集即可,这里如果后续有修改,则可以按照具体情况修改。
那么具体的数据集操作是怎么进行的呢?我们跳入get_imdb():
再跳一次,到了factory.py
\n# Set up voc_<year>_<split>\nfor year in ['2007', '2012']:\n for split in ['train', 'val', 'trainval', 'test']:\n name = 'voc_{}_{}'.format(year, split)\n __sets[name] = (lambda split=split, year=year: pascal_voc(split, year))\n \n# Set up coco_2014_<split>\nfor year in ['2014']:\n for split in ['train', 'val', 'minival', 'valminusminival', 'trainval']:\n name = 'coco_{}_{}'.format(year, split)\n __sets[name] = (lambda split=split, year=year: coco(split, year))\n \n# Set up coco_2015_<split>\nfor year in ['2015']:\n for split in ['test', 'test-dev']:\n name = 'coco_{}_{}'.format(year, split)\n __sets[name] = (lambda split=split, year=year: coco(split, year))\n
我们发现,会有三个循环,怕是coco数据集和pascal_voc数据集在不同年份,他内部的格式也不同,所以要经过这样的处理吧。
先从pascal_voc数据集看起,跳入imdb.init函数,下面代码位于imdb.py:
\n def __init__(self, name, classes=None):\n self._name = name\n self._num_classes = 0\n if not classes:\n self._classes = []\n else:\n self._classes = classes\n self._image_index = []\n self._obj_proposer = 'gt'\n self._roidb = None\n self._roidb_handler = self.default_roidb\n # Use this dict for storing dataset specific config options\n self.config = {}\n
imdb.py这个文件主要就是对读入的数据进行一系列的操作:
初始化部分指定了数据集的名字,初始化类的数量,初始化类的索引标签。指定了proposal的名字为gt,roidb是我们最终得到的结果,先设为NULL,同时,程序设置了一个handler,进行一些操作,一会儿会详细说到。
现在回到pascal_voc.py继续看初始化后的过程:
\nself._year = year\nself._image_set = image_set\n
先指定了数据集年份,然后指定了要用到的东西的Annotation在哪里,我们现在用到的就只有Val和Train,即训练数据和我们的真实数据,就是ground truth:
其中PascalVOC的标注文件在:
...\\Desktop\\FasterRcnn\\Faster-RCNN-TensorFlow-Python3.5-master\\data\\VOCDevkit2007\\VOC2007\\ImageSets\\Main
其中可以打开看一下,trainval这个文件:
\n000005\n000007\n000009\n000012\n000016\n000017\n000019\n000020\n000021\n000023\n000024\n000026\n000030\n
文件中是以这样的形式出现的数据,一共五千条,测试了五千组需要用的案例。trainval中的这些数据就是我们接下来需要训练的数据的一个标签,即对应的图片的名字以及对应的xml信息。
接下来就是指定路径读入相关的信息了。
\nself._devkit_path = self._get_default_path() if devkit_path is None \\\n else devkit_path\nself._data_path = os.path.join(self._devkit_path, 'VOC' + self._year)\n
再后面指定了我们做分类的类别,一共21个类,二十个前景加上一个背景。之后,给每个类的字符串设置一个固定的索引值,这样更加方便接下来的一系列操作:
self._class_to_ind = dict(list(zip(self.classes, list(range(self.num_classes)))))\n
实际上,pascalVOC这么多文件中,这个程序中用到的怕是只有valtrain这一个txt文件了,之后,load一下我们的数据,根据ImageSet中指定的数据,从_data_path路径中读出,并通过x.strip一条一条读出,并把读到的东西以image_index的参数形式返回:
\n def _load_image_set_index(self):\n """\n Load the indexes listed in this dataset's image set file.\n """\n # Example path to image set file:\n # self._devkit_path + /VOCdevkit2007/VOC2007/ImageSets/Main/val.txt\n image_set_file = os.path.join(self._data_path, 'ImageSets', 'Main',\n self._image_set + '.txt')\n assert os.path.exists(image_set_file), \\\n 'Path does not exist: {}'.format(image_set_file)\n with open(image_set_file) as f:\n image_index = [x.strip() for x in f.readlines()]\n return image_index\n
接下来,我们已经看完了pascalVOC的读入过程了,coco数据集也是同理,所以不作赘述,继续回到train.py:
其中set_proposal_method(“gt”),这句话指定了读入的信息就是我们的ground truth。
以下的一句话,有点意思哦:
roidb = get_training_roidb(imdb)\n
然后我们跳入这个方法来看一下:
\ndef get_training_roidb(imdb):\n """Returns a roidb (Region of Interest database) for use in training."""\n if True:\n print('Appending horizontally-flipped training examples...')\n imdb.append_flipped_images()\n print('done')\n \n print('Preparing training data...')\n rdl_roidb.prepare_roidb(imdb)\n print('done')\n \n return imdb.roidb\n
这里将得到的图像都反转了一下,其实就是将图像做了一个镜面对称,这样我们一开始的数据量有5000,翻转之后,我们的数据量就有了一万。
我们仔细来看一下这个翻转的过程,具体再imdb.py中:
\n def append_flipped_images(self):\n num_images = self.num_images\n widths = self._get_widths()\n for i in range(num_images):\n boxes = self.roidb[i]['boxes'].copy()\n oldx1 = boxes[:, 0].copy()\n oldx2 = boxes[:, 2].copy()\n boxes[:, 0] = widths[i] - oldx2 - 1\n boxes[:, 2] = widths[i] - oldx1 - 1\n assert (boxes[:, 2] >= boxes[:, 0]).all()\n entry = {'boxes': boxes,\n 'gt_overlaps': self.roidb[i]['gt_overlaps'],\n 'gt_classes': self.roidb[i]['gt_classes'],\n 'flipped': True}\n self.roidb.append(entry)\n self._image_index = self._image_index * 2\n
好了,到此,我们的数据就算是基本加载完毕了,有一些其他的处理要说明一下,就比如pascalVOC中的:
\n def gt_roidb(self):\n """\n Return the database of ground-truth regions of interest.\n This function loads/saves from/to a cache file to speed up future calls.\n """\n cache_file = os.path.join(self.cache_path, self.name + '_gt_roidb.pkl')\n if os.path.exists(cache_file):\n with open(cache_file, 'rb') as fid:\n try:\n roidb = pickle.load(fid)\n except:\n roidb = pickle.load(fid, encoding='bytes')\n print('{} gt roidb loaded from {}'.format(self.name, cache_file))\n return roidb\n
这个函数的目的是加载数据之后形成一个pickle文件,以后再运行程序的时候,如果数据已经加载就直接从pickle文件中读取,如果没有加载,就继续加载。
...\\Desktop\\FasterRcnn\\Faster-RCNN-TensorFlow-Python3.5-master\\data\\cache
这是缓存的根目录,可以尝试删除试试会出现什么效果哦。
看代码中,指定缓存目录和名字,如果名字存在就先加载完已有的再加载新的数据,如果不存在就从头加载。
好,那么到现在为止,我们已经知道了,选用哪个数据集,加载哪些数据,那些固定的数据在什么位置,以何种形式加载进来,但是,还有一个重要的问题就是,这个数据是怎么以标签的形式具体加载进来的呢?
XML文件是通过解析器解析出来的:
\n def _load_pascal_annotation(self, index):\n """\n Load image and bounding boxes info from XML file in the PASCAL VOC\n format.\n """\n filename = os.path.join(self._data_path, 'Annotations', index + '.xml')\n tree = ET.parse(filename)\n objs = tree.findall('object')\n if not self.config['use_diff']:\n # Exclude the samples labeled as difficult\n non_diff_objs = [\n obj for obj in objs if int(obj.find('difficult').text) == 0]\n # if len(non_diff_objs) != len(objs):\n # print 'Removed {} difficult objects'.format(\n # len(objs) - len(non_diff_objs))\n objs = non_diff_objs\n num_objs = len(objs)\n \n boxes = np.zeros((num_objs, 4), dtype=np.uint16)\n gt_classes = np.zeros((num_objs), dtype=np.int32)\n overlaps = np.zeros((num_objs, self.num_classes), dtype=np.float32)\n # "Seg" area for pascal is just the box area\n seg_areas = np.zeros((num_objs), dtype=np.float32)\n \n # Load object bounding boxes into a data frame.\n for ix, obj in enumerate(objs):\n bbox = obj.find('bndbox')\n # Make pixel indexes 0-based\n x1 = float(bbox.find('xmin').text) - 1\n y1 = float(bbox.find('ymin').text) - 1\n x2 = float(bbox.find('xmax').text) - 1\n y2 = float(bbox.find('ymax').text) - 1\n cls = self._class_to_ind[obj.find('name').text.lower().strip()]\n boxes[ix, :] = [x1, y1, x2, y2]\n gt_classes[ix] = cls\n overlaps[ix, cls] = 1.0\n seg_areas[ix] = (x2 - x1 + 1) * (y2 - y1 + 1)\n \n overlaps = scipy.sparse.csr_matrix(overlaps)\n \n return {'boxes': boxes,\n 'gt_classes': gt_classes,\n 'gt_overlaps': overlaps,\n 'flipped': False,\n 'seg_areas': seg_areas}\n
boxes = np.zeros((num_objs, 4), dtype=np.uint16)
其中,boxes是一个回归框,两个坐标,有n个物体,就是4×n个位置。
gt_classes = np.zeros((num_objs), dtype=np.int32)
其中,有几类,就加载几类进来。overlaps做one hold recording。
seg_areas求面积,暂时还没有用到。
然后就是循环了:这里循环的是一张图片上的n个物体。
现在翻转也做了,数量加倍了,指定了相应的数据了,也都提取出来了。
下面还有一句:
rdl_roidb.prepare_roidb(imdb)\n
再跳一次,到roidb中的prepare_roidb函数中:
\ndef prepare_roidb(imdb):\n """Enrich the imdb's roidb by adding some derived quantities that\n are useful for training. This function precomputes the maximum\n overlap, taken over ground-truth boxes, between each ROI and\n each ground-truth box. The class with maximum overlap is also\n recorded.\n """\n roidb = imdb.roidb\n if not (imdb.name.startswith('coco')):\n sizes = [PIL.Image.open(imdb.image_path_at(i)).size\n for i in range(imdb.num_images)]\n for i in range(len(imdb.image_index)):\n roidb[i]['image'] = imdb.image_path_at(i)\n if not (imdb.name.startswith('coco')):\n roidb[i]['width'] = sizes[i][0]\n roidb[i]['height'] = sizes[i][1]\n # need gt_overlaps as a dense array for argmax\n gt_overlaps = roidb[i]['gt_overlaps'].toarray()\n # max overlap with gt over classes (columns)\n max_overlaps = gt_overlaps.max(axis=1)\n # gt class that had the max overlap\n max_classes = gt_overlaps.argmax(axis=1)\n roidb[i]['max_classes'] = max_classes\n roidb[i]['max_overlaps'] = max_overlaps\n # sanity checks\n # max overlap of 0 => class should be zero (background)\n zero_inds = np.where(max_overlaps == 0)[0]\n assert all(max_classes[zero_inds] == 0)\n # max overlap > 0 => class should not be zero (must be a fg class)\n nonzero_inds = np.where(max_overlaps > 0)[0]\n assert all(max_classes[nonzero_inds] != 0)\n
这里,主要做了什么样的工作呢?
把所有的数据集合到了roidb上并返回。分别指定了路径,图片宽度,高度,重叠率,重叠最大的类别等等。
\nself.data_layer = RoIDataLayer(self.roidb, self.imdb.num_classes)\nself.output_dir = cfg.get_output_dir(self.imdb, 'default')\n
最后,output_dir设置了pickel的默认路径。
datalayer传入了roidb处理完之后的相关数据,和相应类别,并做了一个洗牌操作shuffle。
三、网络架构搭建部分
好,现在先来总结一下Faster RCNN中网络的搭建架构:
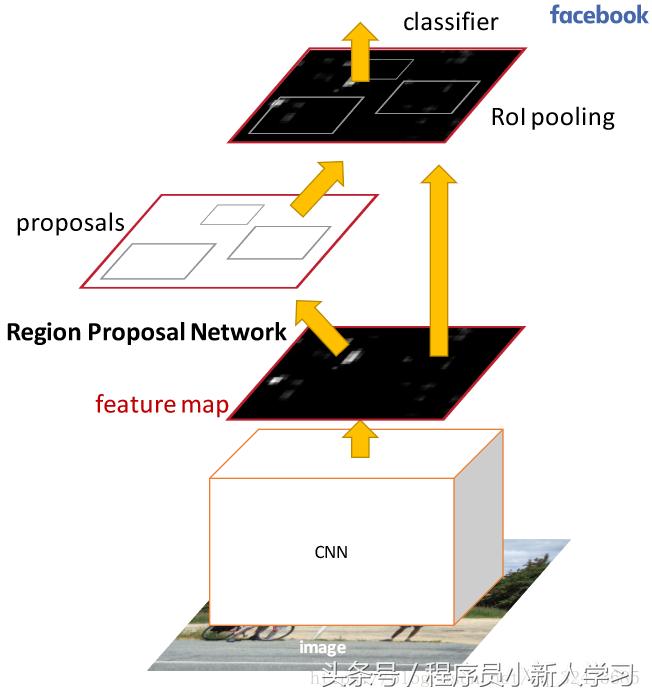
图1
① 搭建了一个conv layers,即一个全卷积网络,在Tensorflow代码中为一个VGG16的结构。
② 从①中迭代几次后的卷积,池化操作后的Feature Map送入RPN(RegionProposal Network)层。
③ 用一个3×3的滑动窗口在②中得到的Feature Map中,(从左到右)滑动,以中间点为锚点,对应到原图,设置三个图像大小,和三个不同的长宽比例,经排列组合,一个锚点位置得到9个不同的对应图像,设所有锚点共计k个对应图像。
④ 用③中得到的k个对应图像,分别执行下述两个操作:回归和分类。回归操作为区分前景背景所用,进行一个二分类操作,故得到2k scores;当回归操作区分出是背景,则无需进行分类操作,如是前景则进行分类操作,得到4k coordinates,每个图像得到的四个值分别是,中心点坐标(x,y),以及该图像的具体长和宽(h,w)。
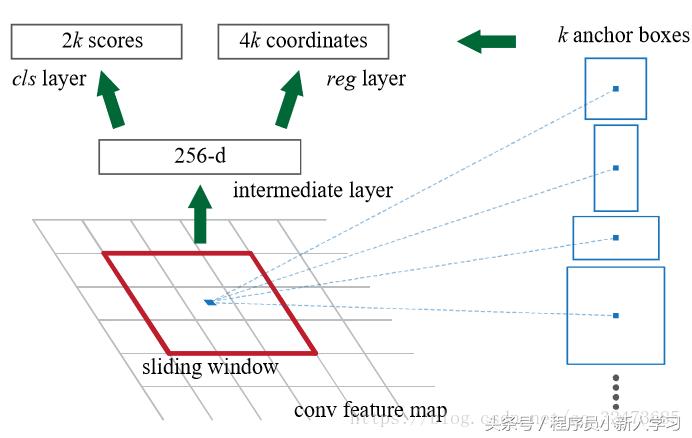
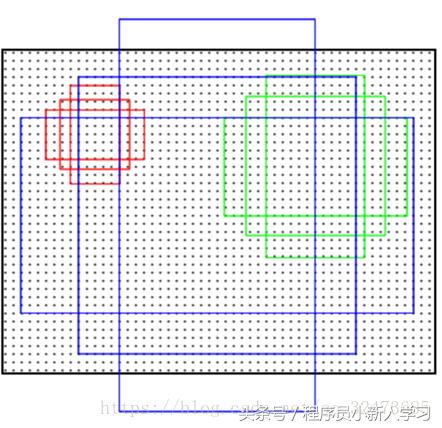
⑤ 经过回归和分类操作之后,进行框的筛选操作,即proposal层做的主要事情。首先,筛掉的框走以下几个步骤:第一,IOU>0.7,即产生的框和原始图像的ground truth的对比,如果重叠率大于0.7,则保留,否则筛掉;第二,NMS非极大值抑制筛选,通过二分类得到的scores值(即为前景的概率值),筛选前n个从大到小的框;第三,越界框筛选。第四,经过以上步骤后,继续筛选score值前m个从大到小的框。
⑥ 对得到的框进行Roi Pooling操作之后,连接一个全连接网络,并在此做一个分类任务,一个回归任务,分类任务为二十一分类,即二十个前景和一个背景,完成整个操作。
好了,到现在为止,回忆结束。
下面,我们正式进入代码:
① 网络结构搭建的大部分代码都位于VGG16.py这个网络中,进入主函数中,第一个Train()交代了数据的部分读入操作,第二个train()交代了网络的训练过程。我们先来解释网络的训练过程。核心代码为第85行:
layers = self.net.create_architecture(sess,"TRAIN", self.imdb.num_classes, tag='default')
其中,create_architecture()函数建立了所有的网络结构。下面,我们跳入该函数。
② 前面指定了一系列卷积,反卷积的参数,核心代码为295行:
rois, cls_prob, bbox_pred = self.build_network(sess,training)
rois为roi pooling层得到的框,cls_prob得到的是最后全连接层的分类score,bbox_pred得到的是二十一分类之后的分类标签。我们继续跳入build_network();
③ 跳入VGG16.py中的第18行同名函数。
好,我们来仔细研究一下这个同名函数:
\n def build_network(self, sess, is_training=True):\n with tf.variable_scope('vgg_16', 'vgg_16'):\n \n # select initializer\n if cfg.FLAGS.initializer == "truncated":\n initializer = tf.truncated_normal_initializer(mean=0.0, stddev=0.01)\n initializer_bbox = tf.truncated_normal_initializer(mean=0.0, stddev=0.001)\n else:\n initializer = tf.random_normal_initializer(mean=0.0, stddev=0.01)\n initializer_bbox = tf.random_normal_initializer(mean=0.0, stddev=0.001)\n \n # Build head\n net = self.build_head(is_training)\n \n # Build rpn\n rpn_cls_prob, rpn_bbox_pred, rpn_cls_score, rpn_cls_score_reshape = self.build_rpn(net, is_training, initializer)\n \n # Build proposals\n rois = self.build_proposals(is_training, rpn_cls_prob, rpn_bbox_pred, rpn_cls_score)\n \n # Build predictions\n cls_score, cls_prob, bbox_pred = self.build_predictions(net, rois, is_training, initializer, initializer_bbox)\n \n self._predictions["rpn_cls_score"] = rpn_cls_score\n self._predictions["rpn_cls_score_reshape"] = rpn_cls_score_reshape\n self._predictions["rpn_cls_prob"] = rpn_cls_prob\n self._predictions["rpn_bbox_pred"] = rpn_bbox_pred\n self._predictions["cls_score"] = cls_score\n self._predictions["cls_prob"] = cls_prob\n self._predictions["bbox_pred"] = bbox_pred\n self._predictions["rois"] = rois\n \n self._score_summaries.update(self._predictions)\n \n return rois, cls_prob, bbox_pred\n
④ 该函数分为了几段,build head,buildrpn,build proposals,build predictions对应的刚好是我们所刚刚叙述的全卷积层,RPN层,Proposal Layer,和最后经过的全连接层。大体结构已有,那么我们就来逐步分析这个这几个函数:
⑤ 全卷积网络层的建立(build head)。在这个Demo中,全卷积网络为五个层,每层有一个卷积,一个池化操作,但是,最后一层操作中,仅有一个卷积操作,无池化操作。
\n # Main network\n # Layer 1\n net = slim.repeat(self._image, 2, slim.conv2d, 64, [3, 3], trainable=False, scope='conv1')\n net = slim.max_pool2d(net, [2, 2], padding='SAME', scope='pool1')\n \n # Layer 2\n net = slim.repeat(net, 2, slim.conv2d, 128, [3, 3], trainable=False, scope='conv2')\n net = slim.max_pool2d(net, [2, 2], padding='SAME', scope='pool2')\n \n # Layer 3\n net = slim.repeat(net, 3, slim.conv2d, 256, [3, 3], trainable=is_training, scope='conv3')\n net = slim.max_pool2d(net, [2, 2], padding='SAME', scope='pool3')\n \n # Layer 4\n net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], trainable=is_training, scope='conv4')\n net = slim.max_pool2d(net, [2, 2], padding='SAME', scope='pool4')\n \n # Layer 5\n net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], trainable=is_training, scope='conv5')\n
由代码中可以看出,这里作者用的silm.conv2d函数进行卷积操作,传统卷积操作为nn模块下的conv2d,max_pool2d进行池化操作。池化用2×2的方格进行,由于卷积层操作不能够缩小图像大小,池化层变为原来的二分之一,所以四个池化层最终变为原来的1/16。
⑦RPN层的建立(build rpn)。_anchor_component()是用来生成九个框的函数。我们继续进入,其中设定了参数,height和width,在这里,都为3,然后通过,tf.py_func()生成9个候选框,generate_anchors_pre中,产生框的具体函数是generate_anchor();generate_anchors()产生位置。建立了位置关系之后,需要映射到原始图像,所以feat_stride为原始图像与这里图像的倍数关系,feat_stride在这里为16。
network.py文件相关代码(从Vgg16.py)跳转来:
\n def _anchor_component(self):\n with tf.variable_scope('ANCHOR_' + 'default'):\n # just to get the shape right\n height = tf.to_int32(tf.ceil(self._im_info[0, 0] / np.float32(self._feat_stride[0])))\n width = tf.to_int32(tf.ceil(self._im_info[0, 1] / np.float32(self._feat_stride[0])))\n anchors, anchor_length = tf.py_func(generate_anchors_pre,\n [height, width,\n self._feat_stride, self._anchor_scales, self._anchor_ratios],\n [tf.float32, tf.int32], name="generate_anchors")\n anchors.set_shape([None, 4])\n anchor_length.set_shape([])\n self._anchors = anchors\n self._anchor_length = anchor_length\n
snippit()中相关代码:
\ndef generate_anchors_pre(height, width, feat_stride, anchor_scales=(8, 16, 32), anchor_ratios=(0.5, 1, 2)):\n """ A wrapper function to generate anchors given different scales\n Also return the number of anchors in variable 'length'\n """\n anchors = generate_anchors(ratios=np.array(anchor_ratios), scales=np.array(anchor_scales))\n A = anchors.shape[0]\n shift_x = np.arange(0, width) * feat_stride\n shift_y = np.arange(0, height) * feat_stride\n shift_x, shift_y = np.meshgrid(shift_x, shift_y)\n shifts = np.vstack((shift_x.ravel(), shift_y.ravel(), shift_x.ravel(), shift_y.ravel())).transpose()\n K = shifts.shape[0]\n # width changes faster, so here it is H, W, C\n anchors = anchors.reshape((1, A, 4)) + shifts.reshape((1, K, 4)).transpose((1, 0, 2))\n anchors = anchors.reshape((K * A, 4)).astype(np.float32, copy=False)\n length = np.int32(anchors.shape[0])\n \n return anchors, length\n
我们现在再回到vgg16.py中的build_rpn()函数,看产生完9个候选框之后的操作。首先经过了一个3×3的卷积,之后用1×1的卷积去进行回归操作,分出前景或是背景,形成分数值,即rpn_cls_score_reshape。再通过softmax函数,得到rpn_clas_prob_reshape,之后,通过reshape化成了标准型,则,变为rpn_bbox_prob。
进行二分类操作和回归操作是并行的,于是用同样1×1的卷积去操作原来的future map,生成长度为4×k,即_num_anchors×4的长度。
最后,将二分类产生的参数以及回归任务产生的参数进行返回,Rpn层就建立好了。
① Proposal层的建立(build proposal)。
\n def build_proposals(self, is_training, rpn_cls_prob, rpn_bbox_pred, rpn_cls_score):\n \n if is_training:\n rois, roi_scores = self._proposal_layer(rpn_cls_prob, rpn_bbox_pred, "rois")\n rpn_labels = self._anchor_target_layer(rpn_cls_score, "anchor")\n \n # Try to have a deterministic order for the computing graph, for reproducibility\n with tf.control_dependencies([rpn_labels]):\n rois, _ = self._proposal_target_layer(rois, roi_scores, "rpn_rois")\n else:\n if cfg.FLAGS.test_mode == 'nms':\n rois, _ = self._proposal_layer(rpn_cls_prob, rpn_bbox_pred, "rois")\n elif cfg.FLAGS.test_mode == 'top':\n rois, _ = self._proposal_top_layer(rpn_cls_prob, rpn_bbox_pred, "rois")\n else:\n raise NotImplementedError\n return rois\n
依然是vgg16.py中的build_proposal函数,我们跳到_proposal_layer的函数中:
network.py:
\n def _proposal_layer(self, rpn_cls_prob, rpn_bbox_pred, name):\n with tf.variable_scope(name):\n rois, rpn_scores = tf.py_func(proposal_layer,\n [rpn_cls_prob, rpn_bbox_pred, self._im_info, self._mode,\n self._feat_stride, self._anchors, self._num_anchors],\n [tf.float32, tf.float32])\n rois.set_shape([None, 5])\n rpn_scores.set_shape([None, 1])\n \n return rois, rpn_scores\n
其中核心代码为,tf.func()中的proposal_layer,我们继续跳入,proposal_layer.py中:
\ndef proposal_layer(rpn_cls_prob, rpn_bbox_pred, im_info, cfg_key, _feat_stride, anchors, num_anchors):\n """A simplified version compared to fast/er RCNN\n For details please see the technical report\n """\n if type(cfg_key) == bytes:\n cfg_key = cfg_key.decode('utf-8')\n \n if cfg_key == "TRAIN":\n pre_nms_topN = cfg.FLAGS.rpn_train_pre_nms_top_n\n post_nms_topN = cfg.FLAGS.rpn_train_post_nms_top_n\n nms_thresh = cfg.FLAGS.rpn_train_nms_thresh\n else:\n pre_nms_topN = cfg.FLAGS.rpn_test_pre_nms_top_n\n post_nms_topN = cfg.FLAGS.rpn_test_post_nms_top_n\n nms_thresh = cfg.FLAGS.rpn_test_nms_thresh\n \n im_info = im_info[0]\n # Get the scores and bounding boxes\n scores = rpn_cls_prob[:, :, :, num_anchors:]\n rpn_bbox_pred = rpn_bbox_pred.reshape((-1, 4))\n scores = scores.reshape((-1, 1))\n proposals = bbox_transform_inv(anchors, rpn_bbox_pred)\n proposals = clip_boxes(proposals, im_info[:2])\n \n # Pick the top region proposals\n order = scores.ravel().argsort()[::-1]\n if pre_nms_topN > 0:\n order = order[:pre_nms_topN]\n proposals = proposals[order, :]\n scores = scores[order]\n \n # Non-maximal suppression\n keep = nms(np.hstack((proposals, scores)), nms_thresh)\n \n # Pick th top region proposals after NMS\n if post_nms_topN > 0:\n keep = keep[:post_nms_topN]\n proposals = proposals[keep, :]\n scores = scores[keep]\n \n # Only support single image as input\n batch_inds = np.zeros((proposals.shape[0], 1), dtype=np.float32)\n blob = np.hstack((batch_inds, proposals.astype(np.float32, copy=False)))\n \n return blob, scores\n
再来回忆一下,我们proposal_layer中做的事情:实际上,再proposal_layer中的任务主要就是筛选合适的框,缩小检测范围,那么,在前文回忆部分的步骤⑤中我们已经说到:第一,筛选与ground truth中,重叠率大于70%的候选框,筛掉其他的候选框,缩小范围;第二,用NMS非极大值抑制,筛选二分类中前n个score值的候选框;第三,筛掉越界框后,再来从前n个从大到小排序的值中筛选一次。好了,那么现在就严格按照这个步骤开始操作:
一开始先指定参数,我们刚才说进行了两次topN操作,所以设定两个参数,一个pre_num_topN和post_num_topN。bbox_transform中为调整框和ground truth大小位置的操作。进入bbox_transform函数:

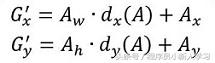
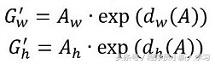
可以看出,该公式调整的时候,先进行了整体平移,再进行了整体缩放,所以,在求出变换因子之后,求出,pred_ctr_x, pred_ctr_y, pred_w以及pred_h。然后返回两个坐标,(x1,y1),(x2,y2)。其中,变换调整到和ground truth差不多的大小。调整办法对应的是论文的上图部分。
代码如下:
bbox_transform.py:
\ndef bbox_transform_inv(boxes, deltas):\n if boxes.shape[0] == 0:\n return np.zeros((0, deltas.shape[1]), dtype=deltas.dtype)\n \n boxes = boxes.astype(deltas.dtype, copy=False)\n widths = boxes[:, 2] - boxes[:, 0] + 1.0\n heights = boxes[:, 3] - boxes[:, 1] + 1.0\n ctr_x = boxes[:, 0] + 0.5 * widths\n ctr_y = boxes[:, 1] + 0.5 * heights\n \n dx = deltas[:, 0::4]\n dy = deltas[:, 1::4]\n dw = deltas[:, 2::4]\n dh = deltas[:, 3::4]\n \n pred_ctr_x = dx * widths[:, np.newaxis] + ctr_x[:, np.newaxis]\n pred_ctr_y = dy * heights[:, np.newaxis] + ctr_y[:, np.newaxis]\n pred_w = np.exp(dw) * widths[:, np.newaxis]\n pred_h = np.exp(dh) * heights[:, np.newaxis]\n \n pred_boxes = np.zeros(deltas.shape, dtype=deltas.dtype)\n # x1\n pred_boxes[:, 0::4] = pred_ctr_x - 0.5 * pred_w\n # y1\n pred_boxes[:, 1::4] = pred_ctr_y - 0.5 * pred_h\n # x2\n pred_boxes[:, 2::4] = pred_ctr_x + 0.5 * pred_w\n # y2\n pred_boxes[:, 3::4] = pred_ctr_y + 0.5 * pred_h\n \n return pred_boxes\n
之后,代码对框先进行了一下出界清除操作,筛掉出界的框,对应代码中clip_transform(),同时选取了前n个框。再接下来nms函数得到keep,之后,在通过topN操作得到非极大值抑制筛选后的框。
\n # Non-maximal suppression\n keep = nms(np.hstack((proposals, scores)), nms_thresh)\n \n # Pick th top region proposals after NMS\n if post_nms_topN > 0:\n keep = keep[:post_nms_topN]\n proposals = proposals[keep, :]\n scores = scores[keep]\n
最后将所得到剩下的框返回,便得到了proposal层之后的留下的框。
接下来,就是筛出来IOU大于70%的框,于是:代码中,_anchor_target_layer()函数中,
\n def _anchor_target_layer(self, rpn_cls_score, name):\n with tf.variable_scope(name):\n rpn_labels, rpn_bbox_targets, rpn_bbox_inside_weights, rpn_bbox_outside_weights = tf.py_func(\n anchor_target_layer,\n [rpn_cls_score, self._gt_boxes, self._im_info, self._feat_stride, self._anchors, self._num_anchors],\n [tf.float32, tf.float32, tf.float32, tf.float32])\n
在进入,anchor_target_layer.py中看一看相关的代码:
\ndef anchor_target_layer(rpn_cls_score, gt_boxes, im_info, _feat_stride, all_anchors, num_anchors):\n """Same as the anchor target layer in original Fast/er RCNN """\n A = num_anchors\n total_anchors = all_anchors.shape[0]\n K = total_anchors / num_anchors\n im_info = im_info[0]\n \n # allow boxes to sit over the edge by a small amount\n _allowed_border = 0\n \n # map of shape (..., H, W)\n height, width = rpn_cls_score.shape[1:3]\n \n # only keep anchors inside the image\n inds_inside = np.where(\n (all_anchors[:, 0] >= -_allowed_border) &\n (all_anchors[:, 1] >= -_allowed_border) &\n (all_anchors[:, 2] < im_info[1] + _allowed_border) & # width\n (all_anchors[:, 3] < im_info[0] + _allowed_border) # height\n )[0]\n \n # keep only inside anchors\n anchors = all_anchors[inds_inside, :]\n \n # label: 1 is positive, 0 is negative, -1 is dont care\n labels = np.empty((len(inds_inside),), dtype=np.float32)\n labels.fill(-1)\n \n # overlaps between the anchors and the gt boxes\n # overlaps (ex, gt)\n overlaps = bbox_overlaps(\n np.ascontiguousarray(anchors, dtype=np.float),\n np.ascontiguousarray(gt_boxes, dtype=np.float))\n argmax_overlaps = overlaps.argmax(axis=1)\n max_overlaps = overlaps[np.arange(len(inds_inside)), argmax_overlaps]\n gt_argmax_overlaps = overlaps.argmax(axis=0)\n gt_max_overlaps = overlaps[gt_argmax_overlaps,\n np.arange(overlaps.shape[1])]\n gt_argmax_overlaps = np.where(overlaps == gt_max_overlaps)[0]\n \n if not cfg.FLAGS.rpn_clobber_positives:\n # assign bg labels first so that positive labels can clobber them\n # first set the negatives\n labels[max_overlaps < cfg.FLAGS.rpn_negative_overlap] = 0\n \n # fg label: for each gt, anchor with highest overlap\n labels[gt_argmax_overlaps] = 1\n \n # fg label: above threshold IOU\n labels[max_overlaps >= cfg.FLAGS.rpn_positive_overlap] = 1\n \n if cfg.FLAGS.rpn_clobber_positives:\n # assign bg labels last so that negative labels can clobber positives\n labels[max_overlaps < cfg.FLAGS.rpn_negative_overlap] = 0\n \n # subsample positive labels if we have too many\n num_fg = int(cfg.FLAGS.rpn_fg_fraction * cfg.FLAGS.rpn_batchsize)\n fg_inds = np.where(labels == 1)[0]\n if len(fg_inds) > num_fg:\n disable_inds = npr.choice(\n fg_inds, size=(len(fg_inds) - num_fg), replace=False)\n labels[disable_inds] = -1\n \n # subsample negative labels if we have too many\n num_bg = cfg.FLAGS.rpn_batchsize - np.sum(labels == 1)\n bg_inds = np.where(labels == 0)[0]\n if len(bg_inds) > num_bg:\n disable_inds = npr.choice(\n bg_inds, size=(len(bg_inds) - num_bg), replace=False)\n labels[disable_inds] = -1\n \n bbox_targets = _compute_targets(anchors, gt_boxes[argmax_overlaps, :])\n \n bbox_inside_weights = np.zeros((len(inds_inside), 4), dtype=np.float32)\n # only the positive ones have regression targets\n bbox_inside_weights[labels == 1, :] = np.array(cfg.FLAGS2["bbox_inside_weights"])\n \n bbox_outside_weights = np.zeros((len(inds_inside), 4), dtype=np.float32)\n if cfg.FLAGS.rpn_positive_weight < 0:\n # uniform weighting of examples (given non-uniform sampling)\n num_examples = np.sum(labels >= 0)\n positive_weights = np.ones((1, 4)) * 1.0 / num_examples\n negative_weights = np.ones((1, 4)) * 1.0 / num_examples\n else:\n assert ((cfg.FLAGS.rpn_positive_weight > 0) &\n (cfg.FLAGS.rpn_positive_weight < 1))\n positive_weights = (cfg.FLAGS.rpn_positive_weight /\n np.sum(labels == 1))\n negative_weights = ((1.0 - cfg.FLAGS.rpn_positive_weight) /\n np.sum(labels == 0))\n bbox_outside_weights[labels == 1, :] = positive_weights\n bbox_outside_weights[labels == 0, :] = negative_weights\n \n # map up to original set of anchors\n labels = _unmap(labels, total_anchors, inds_inside, fill=-1)\n bbox_targets = _unmap(bbox_targets, total_anchors, inds_inside, fill=0)\n bbox_inside_weights = _unmap(bbox_inside_weights, total_anchors, inds_inside, fill=0)\n bbox_outside_weights = _unmap(bbox_outside_weights, total_anchors, inds_inside, fill=0)\n \n # labels\n labels = labels.reshape((1, height, width, A)).transpose(0, 3, 1, 2)\n labels = labels.reshape((1, 1, A * height, width))\n rpn_labels = labels\n \n # bbox_targets\n bbox_targets = bbox_targets \\\n .reshape((1, height, width, A * 4))\n \n rpn_bbox_targets = bbox_targets\n # bbox_inside_weights\n bbox_inside_weights = bbox_inside_weights \\\n .reshape((1, height, width, A * 4))\n \n rpn_bbox_inside_weights = bbox_inside_weights\n \n # bbox_outside_weights\n bbox_outside_weights = bbox_outside_weights \\\n .reshape((1, height, width, A * 4))\n \n rpn_bbox_outside_weights = bbox_outside_weights\n return rpn_labels, rpn_bbox_targets, rpn_bbox_inside_weights, rpn_bbox_outside_weights\n
版权声明:CosMeDna所有作品(图文、音视频)均由用户自行上传分享,仅供网友学习交流。若您的权利被侵害,请联系删除!
本文链接://www.cosmedna.com/article/988838437.html