基础篇要点:算法、数据结构、基础设计模式
1. 二分查找
能够用自己语言描述二分查找算法能够手写二分查找代码能够解答一些变化后的考法算法描述
前提:有已排序数组 A(假设已经做好)定义左边界 L、右边界 R,确定搜索范围,循环执行二分查找(3、4两步)获取中间索引 M = Floor((L+R) /2)中间索引的值 A[M] 与待搜索的值 T 进行比较 ① A[M] == T 表示找到,返回中间索引 ② A[M] > T,中间值右侧的其它元素都大于 T,无需比较,中间索引左边去找,M - 1 设置为右边界,重新查找 ③ A[M] < T,中间值左侧的其它元素都小于 T,无需比较,中间索引右边去找, M + 1 设置为左边界,重新查找当 L > R 时,表示没有找到,应结束循环更形象的描述请参考:binary_search.html
算法实现
public static int binarySearch(int[] a, int t) {\n int l = 0, r = a.length - 1, m;\n while (l <= r) {\n m = (l + r) / 2;\n if (a[m] == t) {\n return m;\n } else if (a[m] > t) {\n r = m - 1;\n } else {\n l = m + 1;\n }\n }\n return -1;\n}测试代码
public static void main(String[] args) {\n int[] array = {1, 5, 8, 11, 19, 22, 31, 35, 40, 45, 48, 49, 50};\n int target = 47;\n int idx = binarySearch(array, target);\n System.out.println(idx);\n}解决整数溢出问题
当 l 和 r 都较大时,l + r 有可能超过整数范围,造成运算错误,解决方法有两种:
int m = l + (r - l) / 2;还有一种是:
int m = (l + r) >>> 1;其它考法
有一个有序表为 1,5,8,11,19,22,31,35,40,45,48,49,50 当二分查找值为 48 的结点时,查找成功需要比较的次数使用二分法在序列 1,4,6,7,15,33,39,50,64,78,75,81,89,96 中查找元素 81 时,需要经过( )次比较在拥有128个元素的数组中二分查找一个数,需要比较的次数最多不超过多少次对于前两个题目,记得一个简要判断口诀: 奇数二分取中间,偶数二分取中间靠左。对于后一道题目,需要知道公式:
n = log_2N = log_{10}N/log_{10}2n=log2N=log10N/log102
其中 n 为查找次数,N 为元素个数
2. 冒泡排序
能够用自己语言描述冒泡排序算法能够手写冒泡排序代码了解一些冒泡排序的优化手段算法描述
依次比较数组中相邻两个元素大小,若 a[j] > a[j+1],则交换两个元素,两两都比较一遍称为一轮冒泡,结果是让最大的元素排至最后重复以上步骤,直到整个数组有序更形象的描述请参考:bubble_sort.html
算法实现
public static void bubble(int[] a) {\n for (int j = 0; j < a.length - 1; j++) {\n // 一轮冒泡\n boolean swapped = false; // 是否发生了交换\n for (int i = 0; i < a.length - 1 - j; i++) {\n System.out.println(比较次数 + i);\n if (a[i] > a[i + 1]) {\n Utils.swap(a, i, i + 1);\n swapped = true;\n }\n }\n System.out.println(第 + j + 轮冒泡\n + Arrays.toString(a));\n if (!swapped) {\n break;\n }\n }\n}优化点1:每经过一轮冒泡,内层循环就可以减少一次优化点2:如果某一轮冒泡没有发生交换,则表示所有数据有序,可以结束外层循环进一步优化
public static void bubble_v2(int[] a) {\n int n = a.length - 1;\n while (true) {\n int last = 0; // 表示最后一次交换索引位置\n for (int i = 0; i < n; i++) {\n System.out.println(比较次数 + i);\n if (a[i] > a[i + 1]) {\n Utils.swap(a, i, i + 1);\n last = i;\n }\n }\n n = last;\n System.out.println(第轮冒泡\n + Arrays.toString(a));\n if (n == 0) {\n break;\n }\n }\n}每轮冒泡时,最后一次交换索引可以作为下一轮冒泡的比较次数,如果这个值为零,表示整个数组有序,直接退出外层循环即可3. 选择排序
选择排序_演示 03:46选择排序_实现 05:44选择排序_vs_冒泡排序能够用自己语言描述选择排序算法能够比较选择排序与冒泡排序理解非稳定排序与稳定排序算法描述
将数组分为两个子集,排序的和未排序的,每一轮从未排序的子集中选出最小的元素,放入排序子集重复以上步骤,直到整个数组有序更形象的描述请参考:selection_sort.html
算法实现
public static void selection(int[] a) {\n for (int i = 0; i < a.length - 1; i++) {\n // i 代表每轮选择最小元素要交换到的目标索引\n int s = i; // 代表最小元素的索引\n for (int j = s + 1; j < a.length; j++) {\n if (a[s] > a[j]) { // j 元素比 s 元素还要小, 更新 s\n s = j;\n }\n }\n if (s != i) {\n swap(a, s, i);\n }\n System.out.println(Arrays.toString(a));\n }\n}优化点:为减少交换次数,每一轮可以先找最小的索引,在每轮最后再交换元素与冒泡排序比较
二者平均时间复杂度都是 O(n^2)O(n2)选择排序一般要快于冒泡,因为其交换次数少但如果集合有序度高,冒泡优于选择冒泡属于稳定排序算法,而选择属于不稳定排序稳定排序指,按对象中不同字段进行多次排序,不会打乱同值元素的顺序不稳定排序则反之稳定排序与不稳定排序
System.out.println(=================不稳定================);\nCard[] cards = getStaticCards();\nSystem.out.println(Arrays.toString(cards));\nselection(cards, Comparator.comparingInt((Card a) -> a.sharpOrder).reversed());\nSystem.out.println(Arrays.toString(cards));\nselection(cards, Comparator.comparingInt((Card a) -> a.numberOrder).reversed());\nSystem.out.println(Arrays.toString(cards));\n\nSystem.out.println(=================稳定=================);\ncards = getStaticCards();\nSystem.out.println(Arrays.toString(cards));\nbubble(cards, Comparator.comparingInt((Card a) -> a.sharpOrder).reversed());\nSystem.out.println(Arrays.toString(cards));\nbubble(cards, Comparator.comparingInt((Card a) -> a.numberOrder).reversed());\nSystem.out.println(Arrays.toString(cards));都是先按照花色排序(♠♥♣♦),再按照数字排序(AKQJ…)
不稳定排序算法按数字排序时,会打乱原本同值的花色顺序
[[♠7], [♠2], [♠4], [♠5], [♥2], [♥5]] \n[[♠7], [♠5], [♥5], [♠4], [♥2], [♠2]]原来 ♠2 在前 ♥2 在后,按数字再排后,他俩的位置变了
稳定排序算法按数字排序时,会保留原本同值的花色顺序,如下所示 ♠2 与 ♥2 的相对位置不变
[[♠7], [♠2], [♠4], [♠5], [♥2], [♥5]] \n[[♠7], [♠5], [♥5], [♠4], [♠2], [♥2]]4. 插入排序
能够用自己语言描述插入排序算法能够比较插入排序与选择排序算法描述
将数组分为两个区域,排序区域和未排序区域,每一轮从未排序区域中取出第一个元素,插入到排序区域(需保证顺序)重复以上步骤,直到整个数组有序更形象的描述请参考:insertion_sort.html
算法实现
// 修改了代码与希尔排序一致\npublic static void insert(int[] a) {\n // i 代表待插入元素的索引\n for (int i = 1; i < a.length; i++) {\n int t = a[i]; // 代表待插入的元素值\n int j = i;\n System.out.println(j);\n while (j >= 1) {\n if (t < a[j - 1]) { // j-1 是上一个元素索引,如果 > t,后移\n a[j] = a[j - 1];\n j--;\n } else { // 如果 j-1 已经 <= t, 则 j 就是插入位置\n break;\n }\n }\n a[j] = t;\n System.out.println(Arrays.toString(a) + + j);\n }\n}与选择排序比较
二者平均时间复杂度都是 O(n^2)O(n2)大部分情况下,插入都略优于选择有序集合插入的时间复杂度为 O(n)O(n)插入属于稳定排序算法,而选择属于不稳定排序提示
插入排序通常被所轻视,其实它的地位非常重要。小数据量排序,都会优先选择插入排序
5. 希尔排序
能够用自己语言描述希尔排序算法算法描述
首先选取一个间隙序列,如 (n/2,n/4 … 1),n 为数组长度每一轮将间隙相等的元素视为一组,对组内元素进行插入排序,目的有二 ① 少量元素插入排序速度很快 ② 让组内值较大的元素更快地移动到后方当间隙逐渐减少,直至为 1 时,即可完成排序更形象的描述请参考:shell_sort.html
算法实现
private static void shell(int[] a) {\n int n = a.length;\n for (int gap = n / 2; gap > 0; gap /= 2) {\n // i 代表待插入元素的索引\n for (int i = gap; i < n; i++) {\n int t = a[i]; // 代表待插入的元素值\n int j = i;\n while (j >= gap) {\n // 每次与上一个间隙为 gap 的元素进行插入排序\n if (t < a[j - gap]) { // j-gap 是上一个元素索引,如果 > t,后移\n a[j] = a[j - gap];\n j -= gap;\n } else { // 如果 j-1 已经 <= t, 则 j 就是插入位置\n break;\n }\n }\n a[j] = t;\n System.out.println(Arrays.toString(a) + gap: + gap);\n }\n }\n}参考资料
//p1-tt.byteimg.com/origin/tos-cn-i-qvj2lq49k0/f44da7d6acf64900a8586dd9c8754ad3.jpg" style="width: 650px;">
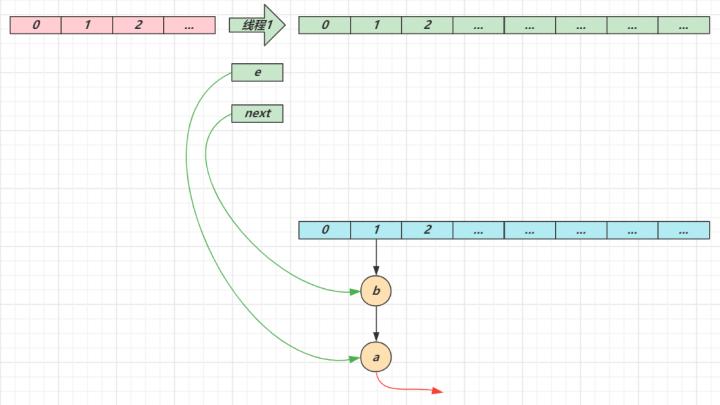
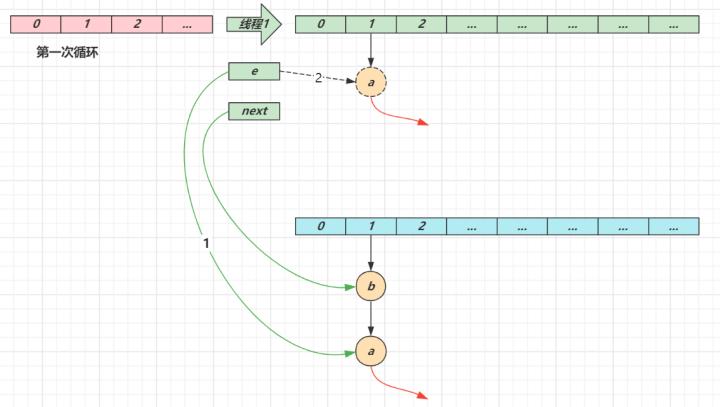
线程2 扩容完成,由于头插法,链表顺序颠倒。但线程1 的临时变量 e 和 next 还引用了这俩节点,还要再来一遍迁移
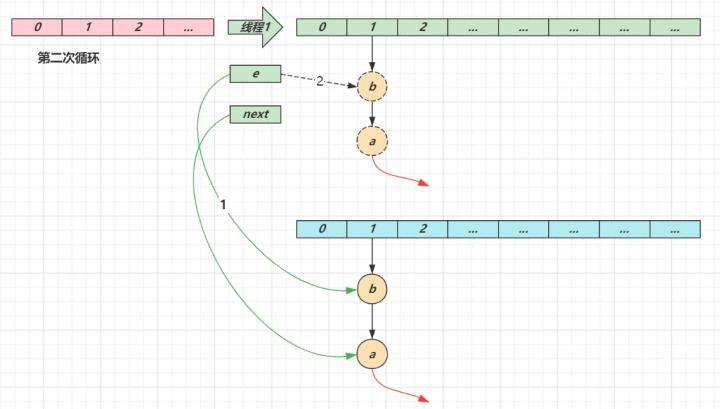
第一次循环循环接着线程切换前运行,注意此时 e 指向的是节点 a,next 指向的是节点 be 头插 a 节点,注意图中画了两份 a 节点,但事实上只有一个(为了不让箭头特别乱画了两份)当循环结束是 e 会指向 next 也就是 b 节点第二次循环next 指向了节点 ae 头插节点 b当循环结束时,e 指向 next 也就是节点 a
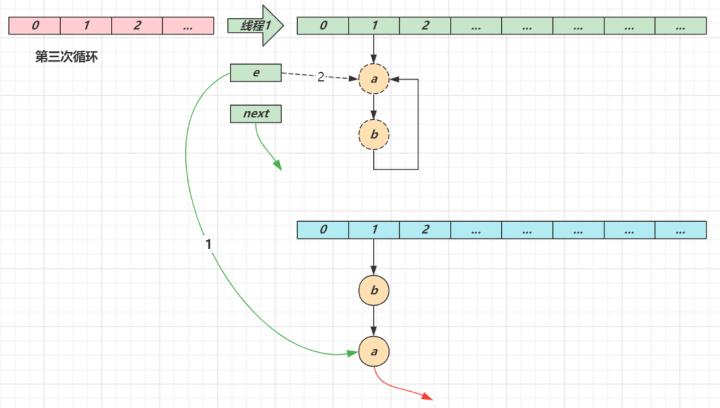
第三次循环next 指向了 nulle 头插节点 a,a 的 next 指向了 b(之前 a.next 一直是 null),b 的 next 指向 a,死链已成当循环结束时,e 指向 next 也就是 null,因此第四次循环时会正常退出
数据错乱(1.7,1.8 都会存在)
代码参考 day01.map.HashMapMissData,具体调试步骤参考视频补充代码说明
day01.map.HashMapDistribution 演示 map 中链表长度符合泊松分布day01.map.DistributionAffectedByCapacity 演示容量及 hashCode 取值对分布的影响day01.map.DistributionAffectedByCapacity#hashtableGrowRule 演示了 Hashtable 的扩容规律day01.sort.Utils#randomArray 如果 hashCode 足够随机,容量是否是 2 的 n 次幂影响不大day01.sort.Utils#lowSameArray 如果 hashCode 低位一样的多,容量是 2 的 n 次幂会导致分布不均匀day01.sort.Utils#evenArray 如果 hashCode 偶数的多,容量是 2 的 n 次幂会导致分布不均匀由此得出对于容量是 2 的 n 次幂的设计来讲,二次 hash 非常重要day01.map.HashMapVsHashtable 演示了对于同样数量的单词字符串放入 HashMap 和 Hashtable 分布上的区别6)key 的设计
key 的设计要求
HashMap 的 key 可以为 null,但 Map 的其他实现则不然作为 key 的对象,必须实现 hashCode 和 equals,并且 key 的内容不能修改(不可变)key 的 hashCode 应该有良好的散列性如果 key 可变,例如修改了 age 会导致再次查询时查询不到
public class HashMapMutableKey {\n public static void main(String[] args) {\n HashMap<Student, Object> map = new HashMap<>();\n Student stu = new Student(张三, 18);\n map.put(stu, new Object());\n\n System.out.println(map.get(stu));\n\n stu.age = 19;\n System.out.println(map.get(stu));\n }\n\n static class Student {\n String name;\n int age;\n\n public Student(String name, int age) {\n this.name = name;\n this.age = age;\n }\n\n public String getName() {\n return name;\n }\n\n public void setName(String name) {\n this.name = name;\n }\n\n public int getAge() {\n return age;\n }\n\n public void setAge(int age) {\n this.age = age;\n }\n\n @Override\n public boolean equals(Object o) {\n if (this == o) return true;\n if (o == null || getClass() != o.getClass()) return false;\n Student student = (Student) o;\n return age == student.age && Objects.equals(name, student.name);\n }\n\n @Override\n public int hashCode() {\n return Objects.hash(name, age);\n }\n }\n}String 对象的 hashCode() 设计
目标是达到较为均匀的散列效果,每个字符串的 hashCode 足够独特字符串中的每个字符都可以表现为一个数字,称为 S_iSi,其中 i 的范围是 0 ~ n - 1散列公式为: S_0∗31^{(n-1)}+ S_1∗31^{(n-2)}+ … S_i ∗ 31^{(n-1-i)}+ …S_{(n-1)}∗31^0S0∗31(n−1)+S1∗31(n−2)+…Si∗31(n−1−i)+…S(n−1)∗31031 代入公式有较好的散列特性,并且 31 * h 可以被优化为即 $32 ∗h -h $即 2^5 ∗h -h25∗h−h即 h≪5 -hh≪5−h11. 单例模式
单例模式_方式1_饿汉式 12:44方式2_枚举饿汉式 11:41单例模式_方式3_懒汉式 07:33单例模式_方式4_DCL懒汉式 05:43单例模式_方式4_DCL懒汉式_为何加volatile 12:02单例模式_方式5_内部类懒汉式 05:35单例模式_在jdk中的体现掌握五种单例模式的实现方式理解为何 DCL 实现时要使用 volatile 修饰静态变量了解 jdk 中用到单例的场景饿汉式
public class Singleton1 implements Serializable {\n private Singleton1() {\n if (INSTANCE != null) {\n throw new RuntimeException(单例对象不能重复创建);\n }\n System.out.println(private Singleton1());\n }\n\n private static final Singleton1 INSTANCE = new Singleton1();\n\n public static Singleton1 getInstance() {\n return INSTANCE;\n }\n\n public static void otherMethod() {\n System.out.println(otherMethod());\n }\n\n public Object readResolve() {\n return INSTANCE;\n }\n}构造方法抛出异常是防止反射破坏单例readResolve() 是防止反序列化破坏单例枚举饿汉式
public enum Singleton2 {\n INSTANCE;\n\n private Singleton2() {\n System.out.println(private Singleton2());\n }\n\n @Override\n public String toString() {\n return getClass().getName() + @ + Integer.toHexString(hashCode());\n }\n\n public static Singleton2 getInstance() {\n return INSTANCE;\n }\n\n public static void otherMethod() {\n System.out.println(otherMethod());\n }\n}枚举饿汉式能天然防止反射、反序列化破坏单例懒汉式
public class Singleton3 implements Serializable {\n private Singleton3() {\n System.out.println(private Singleton3());\n }\n\n private static Singleton3 INSTANCE = null;\n\n // Singleton3.class\n public static synchronized Singleton3 getInstance() {\n if (INSTANCE == null) {\n INSTANCE = new Singleton3();\n }\n return INSTANCE;\n }\n\n public static void otherMethod() {\n System.out.println(otherMethod());\n }\n\n}其实只有首次创建单例对象时才需要同步,但该代码实际上每次调用都会同步因此有了下面的双检锁改进双检锁懒汉式
public class Singleton4 implements Serializable {\n private Singleton4() {\n System.out.println(private Singleton4());\n }\n\n private static volatile Singleton4 INSTANCE = null; // 可见性,有序性\n\n public static Singleton4 getInstance() {\n if (INSTANCE == null) {\n synchronized (Singleton4.class) {\n if (INSTANCE == null) {\n INSTANCE = new Singleton4();\n }\n }\n }\n return INSTANCE;\n }\n\n public static void otherMethod() {\n System.out.println(otherMethod());\n }\n}为何必须加 volatile:
INSTANCE = new Singleton4() 不是原子的,分成 3 步:创建对象、调用构造、给静态变量赋值,其中后两步可能被指令重排序优化,变成先赋值、再调用构造如果线程1 先执行了赋值,线程2 执行到第一个 INSTANCE == null 时发现 INSTANCE 已经不为 null,此时就会返回一个未完全构造的对象内部类懒汉式
public class Singleton5 implements Serializable {\n private Singleton5() {\n System.out.println(private Singleton5());\n }\n\n private static class Holder {\n static Singleton5 INSTANCE = new Singleton5();\n }\n\n public static Singleton5 getInstance() {\n return Holder.INSTANCE;\n }\n\n public static void otherMethod() {\n System.out.println(otherMethod());\n }\n}避免了双检锁的缺点JDK 中单例的体现
Runtime 体现了饿汉式单例Console 体现了双检锁懒汉式单例Collections 中的 EmptyNavigableSet 内部类懒汉式单例ReverseComparator.REVERSE_ORDER 内部类懒汉式单例Comparators.NaturalOrderComparator.INSTANCE 枚举饿汉式单例以上内容参考黑马程序员b站内容整理,如侵删
版权声明:CosMeDna所有作品(图文、音视频)均由用户自行上传分享,仅供网友学习交流。若您的权利被侵害,请联系删除!
本文链接://www.cosmedna.com/article/758735678.html