雷锋网 AI 科技评论按:本文来自著名的计算机视觉教学网站「pyimagesearch」,文章作者为 Adrian Rosebrock。在本文中,Adrian 将就「如何鉴别图像/视频中的真实人脸和伪造人脸」这一问题进行深入的分析,并介绍使用基于 OpenCV 的模型进行活体检测的具体方法。雷锋网 AI 科技评论编译如下。雷锋网
本教程将教授你如何使用 OpenCV 进行活性检测。通过学习,你将能够在人脸识别系统中创建一个可以发现伪造人脸并执行反人脸欺骗的活体检测器。
在过去一年中,本文作者已经写过了多篇人脸识别教程,包括:
基于 OpenCV 的人脸识别(阅读地址://p1-tt.byteimg.com/origin/pgc-image/RN0SLW17RGKSEv.jpg" style="width: 650px;">
图 1:基于 OpenCV 的活体检测。左图是一个我的活体(真人)的视频,而在右图中可以看到我正拿着我的 iPhone(屏幕上有伪造人脸/用来欺骗人脸识别系统的人脸图片)。
人脸识别系统正变得越来越普及。从 iphone / 智能手机上的人脸识别系统,到中国用来进行大规模监控的人脸识别系统——人脸识别变得无处不在。
然而,人脸识别系统却很容易被「具有欺骗性的」和「不真实」的人脸所愚弄。
通过将一个人的照片(无论是打印出来的,或者是显示在智能手机屏幕上的,等等)展示给用于人脸识别的摄像头,可以很容易地骗过人脸识别系统。
为了使人脸识别系统变得更加安全,我们需要检测出这种伪造的/不真实的人脸——而「活体检测」就是被用来指代这种算法的术语。
活体检测的方法有很多,包括:
纹理分析,包括在人脸区域上计算局部二值模式(LBP,//p1-tt.byteimg.com/origin/pgc-image/RN0SLWc5s5zU9b.jpg" style="width: 650px;">
图 2:一个收集到的真实人脸和伪造/欺骗性人脸的例子。左边的视频是一个我的人脸的合法录像。右边是我的笔记本电脑将左边的这段视频录下来的视频。
为了简化我们的例子,我们在本文中构建的活体检测器将重点关注区分屏幕上的真实人脸和欺骗性的人脸。
该算法可以很被容易地扩展到其他类型的欺骗性人脸中,包括打印机或高分辨率打印出来的人脸等。
为了构建活体检测数据集,我将:
1. 使用我的 iPhone,把它调成人像 / 自拍模式。
2. 录制一段大约 25 秒的我自己在办公室内走来走去的视频。
3. 将我的 iPhone 朝向我的桌面重放这个 25 秒的视频,我从桌面的角度录制了这段重放的视频;
4. 这会产生两个示例视频。一个被用作「真实」人脸,另一个被用作「伪造/欺骗性」人脸。
5. 最终,我将人脸检测技术同时应用在了这两组视频上,以提取两类人脸各自的 ROI。
我在本文的「下载」部分为大家提供了真实人脸视频和伪造人脸视频。
你可以直接使用这些视频开始构建数据集,但是我建议你收集更多的数据,从而帮助提升你的活体检测器的鲁棒性和准确率。
通过测试,我确认这个模型会偏向于检测出我自己的人脸——因为所有的模型都是使用我自己的视频训练的,因此这个模型依旧是有意义的。此外,由于我是白种人,我并不奢望该数据集被用于检测其它肤色的人脸时有同样出色的表现。
理想情况下,你可以使用包含多个种族的人脸的数据来训练一个模型。如果读者想要获得更多关于改进活体检测模型的建议,请务必参考下面的「局限性和进一步工作」章节。
在接下来的教程中,你将学习到如何利用我记录下来的数据集,并使用 OpenCV 和深度学习技术得到一个真正的活体检测器。
项目架构
在继续阅读的过程中,读者可以使用「下载」部分提供的链接获取代码、数据集以及活体检测模型,并解压存档。
当你导航到项目的目录时,你会注意到如下所示的架构:
$ tree --dirsfirst --filelimit 10
├── dataset
│ ├── fake [150 entries]
│ └── real [161 entries]
├── face_detector
│ ├── deploy.prototxt
│ └── res10_300x300_ssd_iter_140000.caffemodel
├── pyimagesearch
│ ├── __init__.py
│ └── livenessnet.py
├── videos
│ ├── fake.mp4
│ └── real.mov
├── gather_examples.py
├── train_liveness.py
├── liveness_demo.py
├── le.pickle
├── liveness.model
└── plot.png
6 directories, 12 files
在我们的项目中有四个主要的目录:
「dataset/」:我们的数据集目录包含两类图像:
(1)摄像头对着正在播放我的人脸视频的手机屏幕所拍下的伪造图像。
(2)我用手机自拍的视频中的真实图像。
「face_detector/ 」:包括我们用来定位人脸 ROI 的、预训练好的 Caffe 人脸检测器。
「pyimagesearch/」:该模块包含我们的 LivenessNet 类。
「videos/」:我提供了两个用来训练 LivenessNet 分类器的输入视频。
现在,我们将仔细回顾三个 Python 脚本。在本文的最后,你可以在自己的数据和输入视频上运行这些脚本。按照在本教程中出现的顺序,这三个脚本依次是:
1. 「gather_examples.py」:该脚本从输入的视频文件中抓取人脸的 ROI,并帮助我们创建一个深度学习人脸活体检测数据集。
2.「train_liveness.py」: 如文件名所示,该脚本将训练我们的 LivenessNet 分类器。 我们将使用 Keras 和 TensorFlow 来训练模型。训练的过程会产生以下几个文件:
(1)le.pickle:我们的类标签编码器。
(2)liveness.model:我们用来训练人脸活体检测器的一系列 Keras 模型。
(3)plot.png:训练历史示意图显示出了模型的准确率和损失曲线,我们可以根据它评估我们的模型(即过拟合 / 欠拟合)。
3.「liveness_demo.py」:我们的演示脚本将启动你的网络摄像头拍下视频帧,来进行实时人脸活体检测。
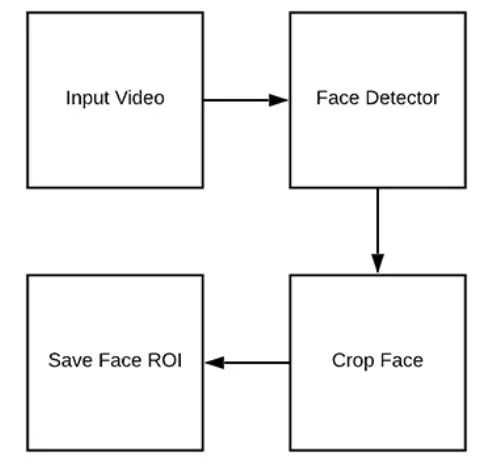
从我们的训练(视频)数据集中检测并提取人脸的 ROI
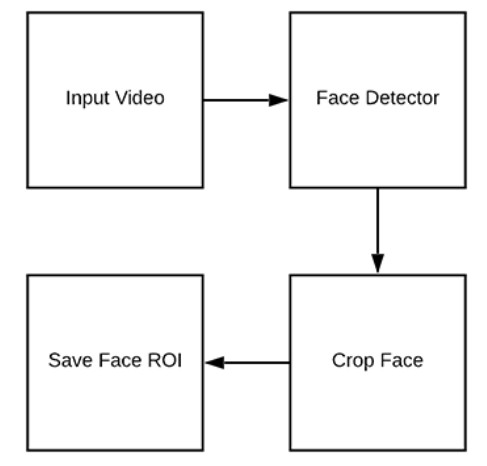
图 3:为了建立一个活体检测数据集,首先需要检测出视频中的人脸 ROI 区域
现在我们可以回顾一下我们初始化的数据集和项目架构,让我们看看如何从输入的视频中提取真实和伪造的人脸图像。
这个脚本的最终目标是向两个目录中填充数据:
1. 「dataset/fake/」:包含「fake.mp4」文件中的人脸 ROI 区域。
2. 「dataset/real/」:包含「real.mov」文件中的人脸 ROI 区域。
基于这些帧,我们接下来将在图像上训练一个基于深度学习的活体检测器。
打开「gather_examples.py」文件并插入下列代码:
# import the necessary packages
import numpy as np
import argparse
import cv2
import os
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser
ap.add_argument("-i", "--input", type=str, required=True,
help="path to input video")
ap.add_argument("-o", "--output", type=str, required=True,
help="path to output directory of cropped faces")
ap.add_argument("-d", "--detector", type=str, required=True,
help="path to OpenCV's deep learning face detector")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
ap.add_argument("-s", "--skip", type=int, default=16,
help="# of frames to skip before applying face detection")
args = vars(ap.parse_args)
第 2-5 行引入了我们需要的安装包。除了内置的 Python 模块,该脚本仅仅需要用到 OpenCV 和 NumPy 。
第 8-19 行代码将解析我们的命令行参数(//p1-tt.byteimg.com/origin/pgc-image/RN0SLYDDa8y7vT.jpg" style="width: 650px;">
图 4:我们的 OpenCV 人脸活体检测数据集。我们将使用 Keras 和 OpenCV 训练一个活体检测模型的演示样例。
请确保你使用了本教程「下载」部分的链接获取到了源代码以及输入视频的示例。
在此基础上,请打开一个终端并执行下面的命令,从而提取出我们的「伪造/欺骗性」的类别所需要的人脸图像:
$ python gather_examples.py --input videos/real.mov --output dataset/real \\
--detector face_detector --skip 1
[INFO] loading face detector...
[INFO] saved datasets/fake/0.png to disk
[INFO] saved datasets/fake/1.png to disk
[INFO] saved datasets/fake/2.png to disk
[INFO] saved datasets/fake/3.png to disk
[INFO] saved datasets/fake/4.png to disk
[INFO] saved datasets/fake/5.png to disk
...
[INFO] saved datasets/fake/145.png to disk
[INFO] saved datasets/fake/146.png to disk
[INFO] saved datasets/fake/147.png to disk
[INFO] saved datasets/fake/148.png to disk
[INFO] saved datasets/fake/149.png to disk
类似地,我们可以为获取「真实」类别的人脸图像进行相同的操作:
$ python gather_examples.py --input videos/fake.mov --output dataset/fake \\
--detector face_detector --skip 4
[INFO] loading face detector...
[INFO] saved datasets/real/0.png to disk
[INFO] saved datasets/real/1.png to disk
[INFO] saved datasets/real/2.png to disk
[INFO] saved datasets/real/3.png to disk
[INFO] saved datasets/real/4.png to disk
...
[INFO] saved datasets/real/156.png to disk
[INFO] saved datasets/real/157.png to disk
[INFO] saved datasets/real/158.png to disk
[INFO] saved datasets/real/159.png to disk
[INFO] saved datasets/real/160.png to disk
由于「真实」的人脸视频比「伪造」的人脸视频文件要更长一些,我们将使用更长的跳帧值来平衡每一类输出的人脸 ROI 的数量。
在执行了上面的脚本后,你应该已经获得了如下所示的图像数据:
伪造人脸:150 张图像
真实人脸:161 张图像
总计:311 张图像
实现我们的深度学习活体检测器「LivenessNet」
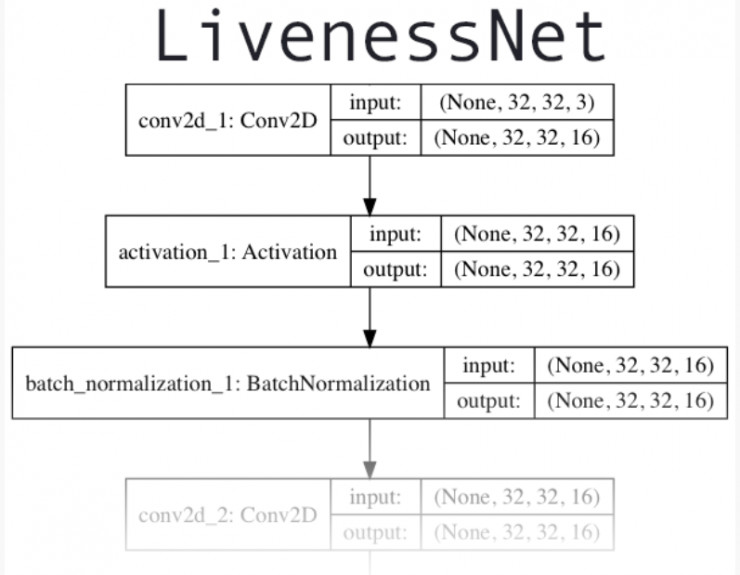
图 5:LivenessNet 的深度学习架构,这是一个被设计用来在图像和视频中检测出活体人脸的卷积神经网络(CNN)。
接下来,我们将实现基于深度学习技术的活体检测器「LivenessNet」。
实质上,「LivenessNet」就是一个简单的卷积神经网络。
出于以下两点原因,我们将刻意让该网络保持尽可能浅的层数和尽可能少的参数:
1. 为了降低在我们的小型数据集上发生过拟合现象的可能性。
2. 为了确保我们的活体检测器能够快速、实时运行(即使在诸如树莓派等计算资源受限的设备上)。
现在,我们将开始实现「LivenessNet」,请打开「livenessnet.py」文件并插入下列代码:
# import the necessary packages
from keras.models import Sequential
from keras.layers.normalization import BatchNormalization
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.layers.core import Activation
from keras.layers.core import Flatten
from keras.layers.core import Dropout
from keras.layers.core import Dense
from keras import backend as K
class LivenessNet:
@staticmethod
def build(width, height, depth, classes):
# initialize the model along with the input shape to be
# "channels last" and the channels dimension itself
model = Sequential
inputShape = (height, width, depth)
chanDim = -1
# if we are using "channels first", update the input shape
# and channels dimension
if K.image_data_format == "channels_first":
inputShape = (depth, height, width)
chanDim = 1
我们将从 Keras 包中引入所有需要的方法(第 2-10 行)。如果你想要进一步了解每一个网络层和函数,请参阅「 Deep Learning for Computer Vision with Python」(网址为://p1-tt.byteimg.com/origin/pgc-image/RN0SLj99fNQ8Lo.jpg" style="width: 650px;">
图 6:训练 LivenessNet 的处理流程。同时使用「真实」人脸和「欺骗性/伪造」人脸图像作为我们的数据集,我们可以使用 OpenCV、Keras 框架以及深度学习技术训练一个活体检测模型。
给定我们的真实/欺骗性人脸图像数据集以及对 LivenessNet 实现,我们现在已经做好了训练该网络的准备:
请打开「train_liveness.py」文件并插入下列代码:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from pyimagesearch.livenessnet import LivenessNet
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from keras.preprocessing.image import ImageDataGenerator
from keras.optimizers import Adam
from keras.utils import np_utils
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import argparse
import pickle
import cv2
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset")
ap.add_argument("-m", "--model", type=str, required=True,
help="path to trained model")
ap.add_argument("-l", "--le", type=str, required=True,
help="path to label encoder")
ap.add_argument("-p", "--plot", type=str, default="plot.png",
help="path to output loss/accuracy plot")
args = vars(ap.parse_args)
我们的人脸活体检测脚本引入了大量的输入(第 2-19 行)。它们分别是:
「matplotlib」:用以生成训练情况示意图。在第 3 行中,我们将后端指定为「Agg」,从而使我们可以很容易地将示意图写入磁盘。
「LivenessNet」:我们在前面的章节定义过的活体检测卷积神经网络。
「train_test_split」:从 scikit-learn 引入的函数,它构造了用于训练和测试的数据划分。
「classification_report」:同样从 scikit-learn 引入的函数,它将生成一个描述我们模型性能的简短的统计报告。
「ImageDataGenerator」:用于进行数据增强,向我们提供批量的随机突变增强的图像。
「Adam」:一个非常适用于该模型的优化器(可选方案包括随机梯度下降算法(SGD)、RMSprop 等)。
「paths」:从我的「imutils」包中引入,该模块可以帮助我们收集磁盘上所有图像文件的路径。
「pyplot」:用来生成一个精美的训练过程示意图。
「numpy」:一个用于 Python 的数字处理开发库,它也是 OpenCV 的所需要的。
「argparse」:用于处理命令行参数(相关阅读://p1-tt.byteimg.com/origin/pgc-image/RN0SLjOEQ8X2Dl.jpg" style="width: 650px;">
图 6:使用 OpenCV、Keras 以及深度学习技术训练一个人脸活体检测模型的训练过程示意图。
如结果所示,我们在验证集上实现 99% 的活体检测准确率。
整合一下:通过 OpenCV 实现活体检测
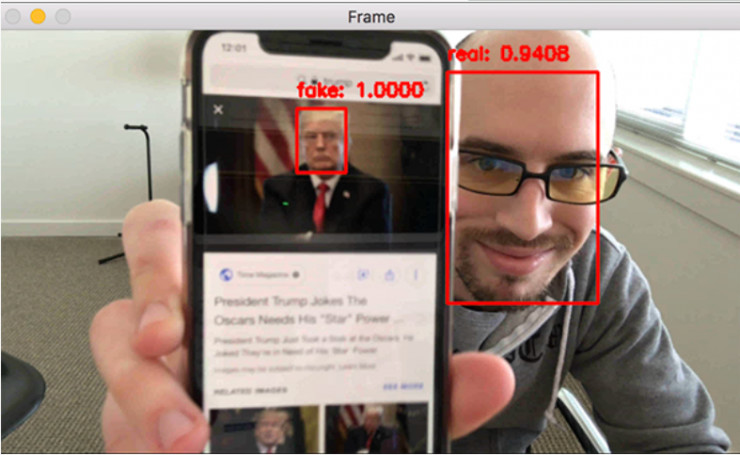
图 7:使用 OpenCV 和深度学习技术实现人脸活体检测
最后,我们需要做的是将以上内容整合起来:
1. 连接到我们的网络摄像头/视频流
2. 将人脸检测应用到每一帧上
3. 对每一个检测到的人脸应用我们的活体检测模型
请打开「liveness_demo.py」文件并插入下列代码:
# import the necessary packages
from imutils.video import VideoStream
from keras.preprocessing.image import img_to_array
from keras.models import load_model
import numpy as np
import argparse
import imutils
import pickle
import time
import cv2
import os
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser
ap.add_argument("-m", "--model", type=str, required=True,
help="path to trained model")
ap.add_argument("-l", "--le", type=str, required=True,
help="path to label encoder")
ap.add_argument("-d", "--detector", type=str, required=True,
help="path to OpenCV's deep learning face detector")
ap.add_argument("-c", "--confidence", type=float, default=0.5,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args)
第 2-11 行输入了我们需要的安装包。 注意,我们将使用:
「VideoStream」:用来连接到我们的摄像头。
「img_to_array」:令我们的视频帧存储在一个兼容的数组格式中。
「load_model」:加载我们的序列化 Keras 模型。
「imutils」:包含一些方便使用的工具函数。
「cv2」:绑定 OpenCV。
在第 14-23 行中,我们将解析命令行参数:
「--model」:我们预训练好的用于活体检测的 Keras 模型的路径。
「--le」:标签编码器的路径。
「--detector」:用于计算出人脸 ROI 的 OpenCV 的深度学习人脸检测器的路径。
「--confidence」:过滤掉较弱的检测结果的最小阈值概率。
接下来,我们将初始化人脸检测器、LivenessNet 模型 + 标签编码器,以及我们的视频流:
# load our serialized face detector from disk
print("[INFO] loading face detector...")
protoPath = os.path.sep.join([args["detector"], "deploy.prototxt"])
modelPath = os.path.sep.join([args["detector"],
"res10_300x300_ssd_iter_140000.caffemodel"])
net = cv2.dnn.readNetFromCaffe(protoPath, modelPath)
# load the liveness detector model and label encoder from disk
print("[INFO] loading liveness detector...")
model = load_model(args["model"])
le = pickle.loads(open(args["le"], "rb").read)
# initialize the video stream and allow the camera sensor to warmup
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start
time.sleep(2.0)
在第 27-30 行加载 OpenCV 的人脸检测器。
在此基础上,我们加载了序列化、预训练的 LivenessNet 模型以及标签编码器(第 34-35 行)。
在第 39 和 40 行中,我们的「VideoStream」对象被实例化,并且允许摄像头预热 2 秒。
至此,是时候开始循环输入视频帧来检测「真实」人脸和「伪造/欺骗性」人脸了:
# loop over the frames from the video stream
while True:
# grab the frame from the threaded video stream and resize it
# to have a maximum width of 600 pixels
frame = vs.read
frame = imutils.resize(frame, width=600)
# grab the frame dimensions and convert it to a blob
(h, w) = frame.shape[:2]
blob = cv2.dnn.blobFromImage(cv2.resize(frame, (300, 300)), 1.0,
(300, 300), (104.0, 177.0, 123.0))
# pass the blob through the network and obtain the detections and
# predictions
net.setInput(blob)
detections = net.forward
第 43 行开启了一个无限的「while」循环代码块,我们首先读取某一帧然后对其进行放缩(第46 和 47 行)。
重新定义图像尺寸后,获取帧的尺寸,以便稍后执行缩放(第 50 行)。
使用 OpenCV 的「blobFromImage」函数(//p1-tt.byteimg.com/origin/pgc-image/RN0SLk3H6fxDPf.jpg" style="width: 650px;">
在这里,你可以看到我们的活体检测器成功地将真实人脸和伪造人脸区分了开来。
我在下面的视频汇中展示了一段更长的演示样例。
视频观看地址:https://youtu.be/MPedzm6uOMA
局限性、改进和未来的工作
我们的活性检测器的主要限制实际上是数据集比较有限——总共只有 311 张图像(包含「真实」类的 161 张图像和「伪造」类的 150 张图像)。
这项工作的一项扩展,就是收集额外的训练数据,更具体地说,可以收集来自于你、我之外的人的图像/视频帧数据。
请记住,这里使用的示例数据集只包含一个人(我自己)的人脸。我是白人/白种人,而你应该收集其他种族和肤色的人脸训练数据。
我们的活体检测器只在屏幕上具有欺骗性攻击的人脸进行训练,而没有对打印出来的图像或照片进行训练。因此,我的第三个建议是,除了简单的屏幕录制回放之外,还要收集其它种类的图像/人脸资源。
最后,我想说:想实现活体检测并没有什么捷径。
最好的活体检测器应该包含多种活体检测方法(请参阅上面的「什么是活体检测, 我们为什么需要它?」一节)。
你需要花点时间来考虑和评估你自己的项目、指导方针和需求。在某些情况下,你可能只需要用到基本的眨眼检测启发方法。
而在其他情况下,你需要将基于深度学习的活体检测与其它启发式方法相结合。
不要急于进行人脸识别和活体检测。你克制一下自己,花点时间考虑自己独特的项目需求。这样的话将确保你获得更好、更准确的结果。
总结
通过学习本教程,你就可以掌握如何使用 OpenCV 进行活体检测。
现在通过使用活体检测器,你就可以检测出伪造的人脸,并在你自己的人脸识别系统中执行反人脸欺骗过程。
在活体检测器的创建过程中,我们用到了 OpenCV、深度学习技术以及 Python 语言。
首先,我们需要收集自己的「真实 vs 伪造」人脸数据集。为了完成该任务,我们要做到:
1. 用智能手机录制一段我们自己的视频(即「真实」人脸)。
2. 将我们的智能手机屏幕展示给笔记本电脑/桌面电脑的摄像头,重放在上一步中录制的同一个视频,然后使用你的网络摄像头录下视频回放(即「伪造」人脸)。
3. 将人脸检测技术同时应用到上面两个视频集合中,以构建最终的活体检测数据集。
在构建好数据集后,我们实现了「LivenessNet」——它是一个用 Keras 和深度学习技术实现的卷积神经网络。
我们特意将网络设计得很浅,这是为了确保:
1. 在我们的小型数据集上减少过拟合现象。
2. 模型能够实时运行(包括在树莓派等硬件上)。
总的来说,该活体检测器在我们的验证集上的表现,准确率高达 99% 。
为了演示完整的活体检测工作流程,我们创建了一个 Python + OpenCV 的脚本,该脚本加载了我们的活体检测程序并将其应用在了实时视频流上。
正如我们的演示样例所示,我们的活体检测器能够区分真假人脸。
希望你喜欢这篇使用 OpenCV 进行活体检测的文章!
资源下载链接:https://www.getdrip.com/forms/321809846/submissions
via: https://www.pyimagesearch.com/2019/03/11/liveness-detection-with-opencv
版权声明:CosMeDna所有作品(图文、音视频)均由用户自行上传分享,仅供网友学习交流。若您的权利被侵害,请联系删除!
本文链接://www.cosmedna.com/article/655233562.html