摘要:这篇文章将详细介绍生成对抗网络GAN的基础知识,包括什么是GAN、常用算法(CGAN、DCGAN、infoGAN、WGAN)、发展历程、预备知识,并通过Keras搭建最简答的手写数字图片生成案。
一.GAN简介
1.GAN背景知识
Ian Goodfellow 因提出了生成对抗网络(GANs,Generative Adversarial Networks)而闻名, GAN最早由Ian Goodfellow于2014年提出,以其优越的性能,在不到两年时间里,迅速成为一大研究热点。他也被誉为“GANs之父”,甚至被推举为人工智能领域的顶级专家。

实验运行结果如下图所示,生成了对应的图像。

或许,你对这个名字还有些陌生,但如果你对深度学习有过了解,你就会知道他。最畅销的这本《深度学习》作者正是Ian Goodfellow大佬。

在2016年,Ian Goodfellow大佬又通过50多页的论文详细介绍了GAN,这篇文章也推荐大家去学习。

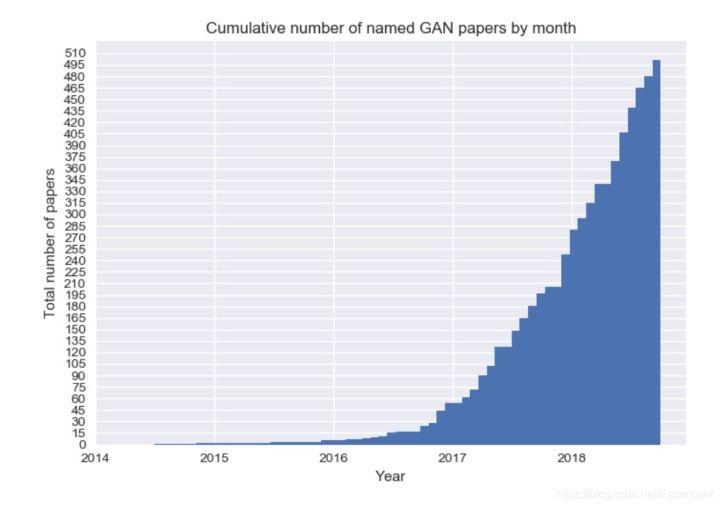
Yann LeCun称GAN为“过去十年机器学习界最有趣的idea”。GAN在github上的火热程度如下图所示,呈指数增涨,出现各种变形。当然,其中也存在很多比较水的文章,推荐大家尽量学习比较经典的模型。
2.GAN原理解析
首先,什么是GAN?
GANs(Generativeadversarial networks,对抗式生成网络)可以把这三个单词拆分理解。
Generative:生成式模型Adversarial:采取对抗的策略Networks:网络(不一定是深度学习)正如shunliz大佬总结:GANs是一类生成模型,从字面意思不难猜到它会涉及两个“对手”,一个称为Generator(生成者),一个称为Discriminator(判别者)。Goodfellow最初arxiv上挂出的GAN tutorial文章中将它们分别比喻为伪造者(Generator)和警察(Discriminator)。伪造者总想着制造出能够以假乱真的钞票,而警察则试图用更先进的技术甄别真假。两者在博弈过程中不断升级自己的技术。从博弈论的角度来看,如果是零和博弈(zero-sum game),两者最终会达到纳什均衡(Nash equilibrium),即存在一组策略(g, d),如果Generator不选择策略g,那么对于Discriminator来说,总存在一种策略使得Generator输得更惨;同样地,将Generator换成Discriminator也成立。如果GANs定义的lossfunction满足零和博弈,并且有足够多的样本,双方都有充足的学习能力情况,在这种情况下,Generator和Discriminator的最优策略即为纳什均衡点,也即:Generator产生的都是“真钞”(材料、工艺技术与真钞一样,只是没有得到授权),Discriminator会把任何一张钞票以1/2的概率判定为真钞。
那么,GAN究竟能做什么呢?
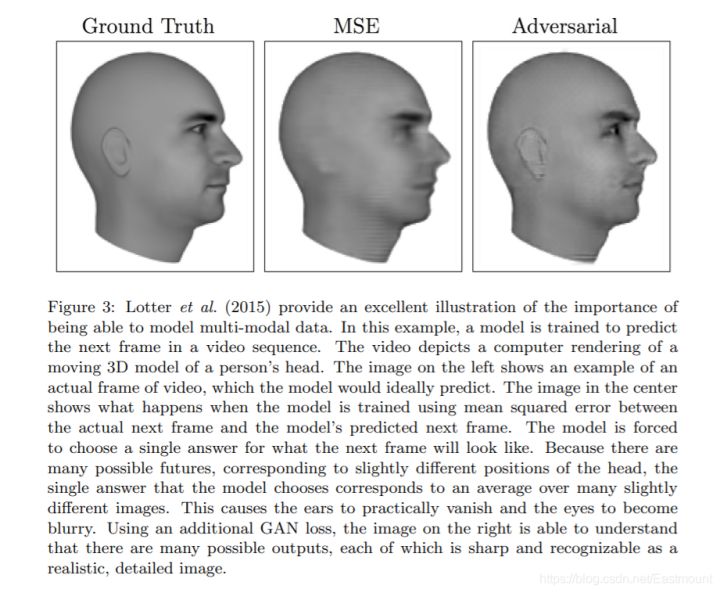
如下图所示,这是一张非常有意思的图,最左边是真实的图,我们希望去预测视频后几帧的模样,中间这张图是用MSE做的,最右边的图是生成对抗网络做的。通过细节分析,我们可以看到中间这张图的耳朵和眼睛都是模糊的,而GAN生成的效果明显更好。
接着我们在看一个超分辨率的实例。首先给出一张超分辨率的图,最左边的图像是原始高分辨率图像(original),然后要对其进行下采样,得到低分辨率图像,接着采用不同的方法对低分辨率图像进行恢复,具体工作如下:
bicubic:第二张图是bicubic方法恢复的图像。经过压缩再拉伸还原图像,通过插值运算实现,但其图像会变得模糊。SRResNet:第三张图像是通过SRResNet实现的恢复,比如先压缩图像再用MSE和神经网络学习和真实值的差别,再进行恢复。(SRResNet is a neural network trained with mean squared error)SRGAN:第四张图是通过SRGAN实现的,其恢复效果更优。SRGAN是在GAN基础上的改进,它能够理解有多个正确的答案,而不是在许多答案中给出一个最佳输出。
我们注意观察图像头部雕饰的细节,发现GAN恢复的轮廓更清晰。该实验显示了使用经过训练的生成模型从多模态分布生成真实样本的优势。

在这里,我们也科普下超分辨率——SRCNN。
它最早是在论文《Learning a Deep Convolutional Network for Image Super-Resolution》中提出,这篇文章的四位作者分别为董超,Chen Change Loy,何凯明,汤晓欧,也都是妥妥的大神。从CV角度来看,这篇论文是真的厉害。
现假设要解决一个问题:能不能解决超分辨率,从一个低分辨率的图像恢复成一个高分辨率的图像,那怎么做呢? 他们通过增加两个卷积层的网络就解决了一个实际问题,并且这篇文章发了一个顶会。
//p1-tt.byteimg.com/origin/tos-cn-i-qvj2lq49k0/574f1a2dadde4f8cb31f7f26e173c964.jpg" style="width: 650px;">更详细的介绍参考知乎oneTaken大佬的分享。
这是第一篇将端到端的深度学习训练来进行超分的论文,整篇论文的的过程现在看起来还是比较简单的,先将低分辨率图片双三次插值上采样到高分辨率图片,然后再使用两层卷积来进行特征映射,最后使用MSE来作为重建损失函数进行训练。从现在来看很多东西还是比较粗糙的,但这篇论文也成为很多超分论文的baseline。整篇论文的创新点有:(1) 使用了一个卷积神经网络来进行超分,端到端的学习低分辨率与超分辨率之间的映射。(2) 将提出的神经网络模型与传统的稀疏编码方法之间建立联系,这种联系还指导用来设计神经网络模型。(3) 实验结果表明深度学习方法可以用于超分中,可以获得较好的质量和较快的速度。整个的模型架构非常的简单,先是对于输入图片进行双三次插值采样到高分辨空间,然后使用一层卷积进行特征提取,再用ReLU进行非线性映射,最后使用一个卷积来进行重建,使用MSE来作为重建损失。中间一个插曲是将传统用于超分的稀疏编码算法进行了延伸,可以看作是一种具有不同非线性映射的卷积神经网络模型。
3.GAN经典案例
GNN究竟能做什么呢?
下面来看看一些比较有趣的GAN案例。
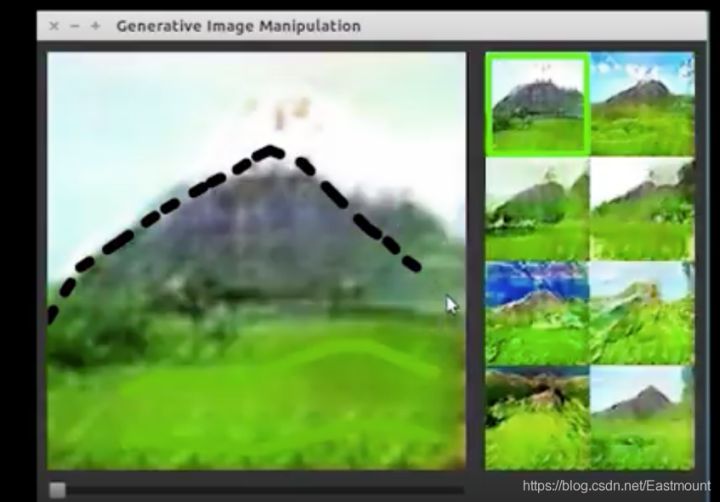
首先是一个视频,这篇文章中介绍了Zhu等人开发了交互式(interactive)生成对抗网络(iGAN),用户可以绘制图像的粗略草图,就使用GAN生成相似的真实图像。在这个例子中,用户潦草地画了几条绿线,就把它变成一块草地,用户再花了一条黑色的三角形,就创建了一个山包。
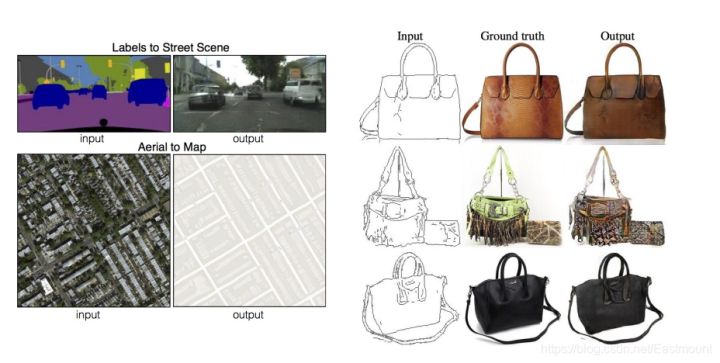
另一个比较经典的案例是左侧输入的皮包简图最终生成接近真实包的图像,或者将卫星照片转换成地图,将阈值车辆图像转换为现实中逼真的图像。
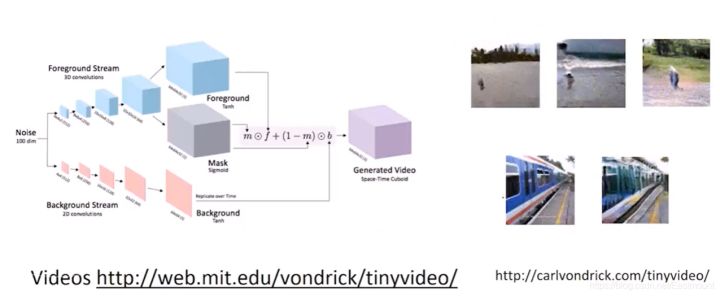
再比如通过GAN去预测视频中下一帧动画会发生什么,比如右下角给了一张火车的静态图片,会生成一段火车跑动的动态视频。
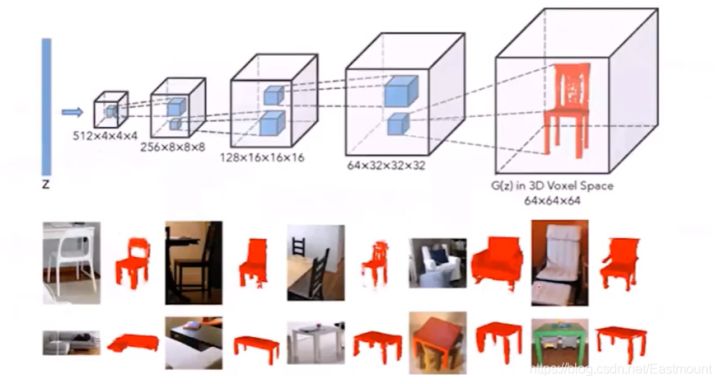
Wu等在NIPS 2016中通过GAN实现了用噪声去生成一张3D椅子模型。
下图是starGAN。左侧输入的是一张人脸,然后GAN会生成对应的喜怒哀乐表情,这篇文章的创新不是说GAN能做这件事,而是提出一个方案,所有的核心功能都在一起,只训练一个生成器,即不是生成多对多的生成器,而只训练一个生成器就能实现这些功能。
starGAN转移从RaFD数据集中学到的知识,在CelebA数据集上的多域图像转换结果。第一和第六列显示输入图像,其余列是由starGAN生成的图像。请注意,这些图像是由一个单一的生成器网络生成的,而愤怒、快乐和恐惧等面部表情标签都来自RaFD,而不是CelebA。

二.GAN预备知识
为什么要讲预备知识呢?
通过学习神经网络的基础知识,能进一步加深我们对GAN的理解。当然,看到这篇文章的读者可能很多已经对深度学习有过了解或者是大佬级别,这里也照顾下初学者,普及下GAN相关基础知识。这里推荐初学者去阅读作者该系列文章,介绍了很多基础原理。
1.什么是神经网络
首先,深度学习就是模拟人的脑神经(生物神经网络),比如下图左上方①中的神经元,可以认为是神经网络的接收端,它有很多的树突接收信号,对应Neuron的公式如下:
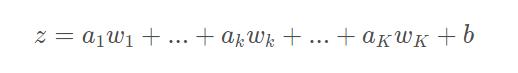
其中,a表示信号(树突接收),w表示对应的权重,它们会进行加权求和组合且包含一个偏置b。通过激活函数判断能否给下一个神经元传递信号。
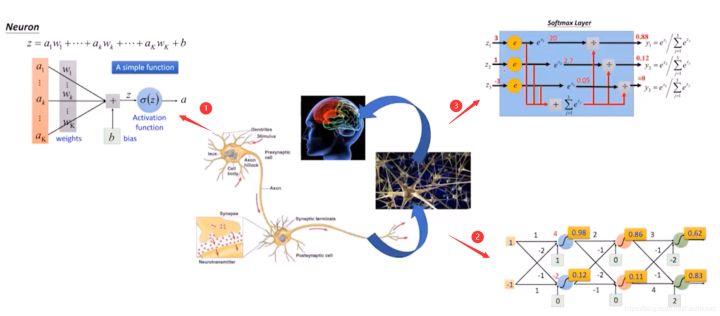
有了这个神经元之后,我们需要构建网络,如右下方②所示。经过一层、两层、三层神经网络,我们最后会有一个判断,如右上方③所示,经过Softmax函数判断,决策这幅图像是什么,比如猫或狗。
其次,深度学习有哪些知识点呢?
深度学习的网络设计如下图所示:
神经网络常见层全连接层、激活层、BN层、Dropout层、卷积层、池化层、循环层、Embedding层、Merege层等网络配置损失函数、优化器、激活函数、性能评估、初始化方法、正则项等网络训练流程预训练模型、训练流程、数据预处理(归一化、Embedding)、数据增强(图片翻转旋转曝光生成海量样本)等
补充:深度学习的可解释性非常差,很多时候不知道它为什么正确。NLP会议上也经常讨论这个可解释性到底重不重要。个人认为,如果用传统的方法效果能达到80%,而深度学习如果提升非常大,比如10%,个人感觉工业界还是会用的,因为能提升性能并解决问题。除非比如风控任务,美团检测异常刷单情况,此时需要准确的确认是否刷单。
2.全连接层
隐藏层的输入和输出都有关联,即全连接层的每一个结点都与上一层的所有结点相连,用来把前边提取到的特征综合起来。由于其全相连的特性,一般全连接层的参数也是最多的。
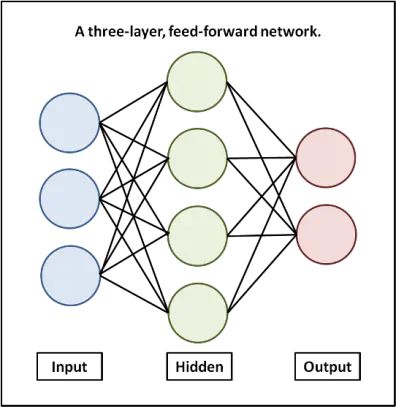
全连接层包括神经元的计算公式、维度(神经元个数)、激活函数、权值初始化方法(w、b)、正则项。
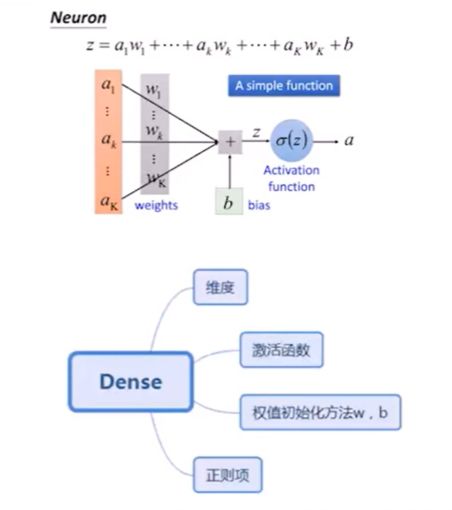
3.激活函数
激活函数(activation function)会让某一部分神经元先激活,然后把激活的信息传递给后面一层的神经系统中。比如,某些神经元看到猫的图片,它会对猫的眼睛特别感兴趣,那当神经元看到猫的眼睛时,它就被激励了,它的数值就会被提高。
激活函数相当于一个过滤器或激励器,它把特有的信息或特征激活,常见的激活函数包括softplus、sigmoid、relu、softmax、elu、tanh等。
对于隐藏层,我们可以使用relu、tanh、softplus等非线性关系;对于分类问题,我们可以使用sigmoid(值越小越接近于0,值越大越接近于1)、softmax函数,对每个类求概率,最后以最大的概率作为结果;对于回归问题,可以使用线性函数(linear function)来实验。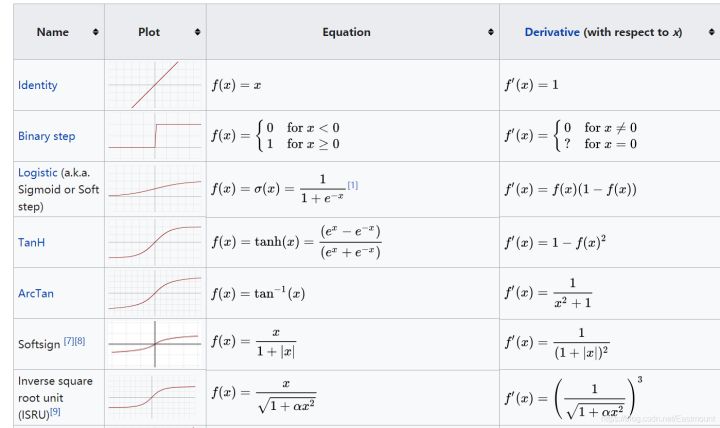
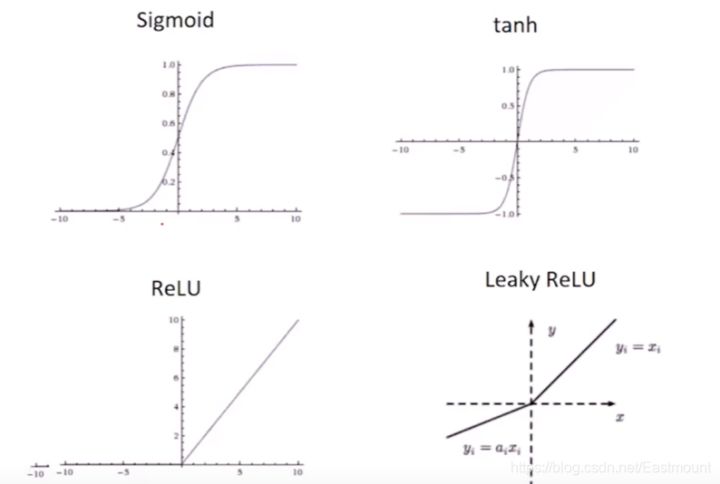
常用的激活函数Sigmoid、tanh、ReLU、Leaky ReLU曲线如下图所示:
4.反向传播
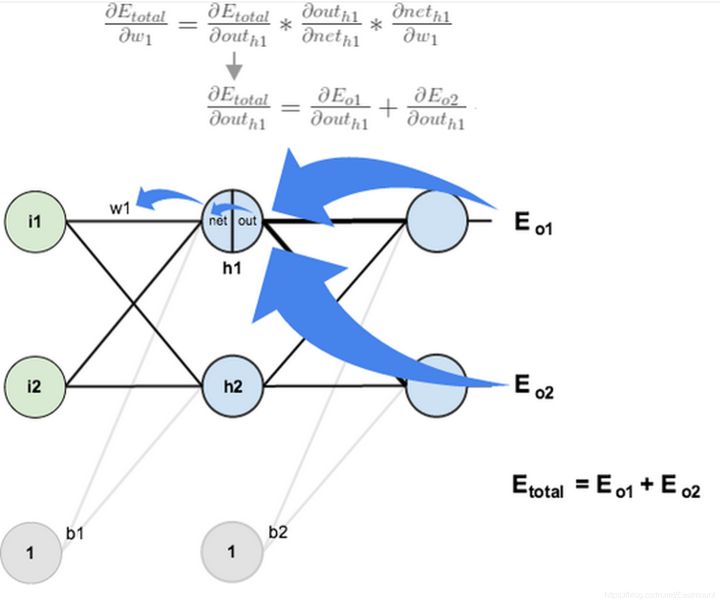
BP神经网络是非常经典的网络,这里通过知乎EdisonGzq大佬的两张图来解释神经网络的反向传播。对于一个神经元而言,就是计算最后的误差传回来对每个权重的影响,即计算每层反向传递的梯度变化。
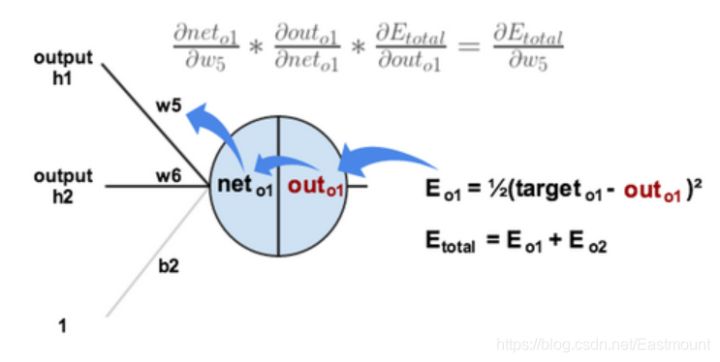
对于多个神经元而言,它是两条线的输出反向传递,如下图所示Eo1和Eo2。
5.优化器选择
存在梯度变化后,会有一个迭代的方案,这种方案会有很多选择。优化器有很多种,但大体分两类:
一种优化器是跟着梯度走,每次只观察自己的梯度,它不带重量一种优化器是带重量的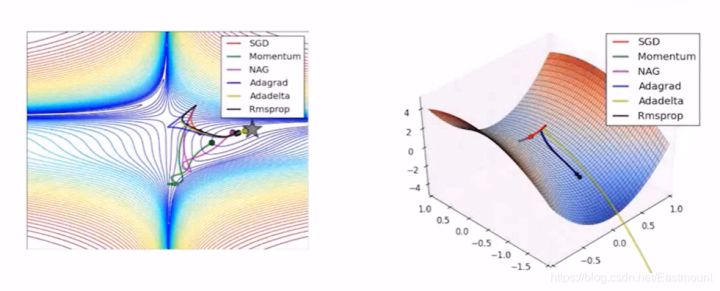
class tf.train.Optimizer是优化器(optimizers)类的基类。优化器有很多不同的种类,最基本的一种是GradientsDescentOptimizer,它也是机器学习中最重要或最基础的线性优化。七种常见的优化器包括:
class tf.train.GradientDescentOptimizerclass tf.train.AdagradOptimizerclass tf.train.AdadeltaOptimizerclass tf.train.MomentumOptimizerclass tf.train.AdamOptimizerclass tf.train.FtrlOptimizerclass tf.train.RMSPropOptimizer下面简单介绍其中四个常用的优化器:
GradientDescentOptimizer梯度下降GD取决于传进数据的size,比如只传进去全部数据的十分之一,Gradient Descent Optimizer就变成了SGD,它只考虑一部分的数据,一部分一部分的学习,其优势是能更快地学习到去往全局最小量(Global minimum)的路径。MomentumOptimizer它是基于学习效率的改变,它不仅仅考虑这一步的学习效率,还加载了上一步的学习效率趋势,然后上一步加这一步的learning_rate,它会比GradientDescentOptimizer更快到达全局最小量。AdamOptimizerAdam名字来源于自适应矩估计(Adaptive Moment Estimation),也是梯度下降算法的一种变形,但是每次迭代参数的学习率都有一定的范围,不会因为梯度很大而导致学习率(步长)也变得很大,参数的值相对比较稳定。Adam算法利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。RMSPropOptimizerGoogle用它来优化阿尔法狗的学习效率。RMSProp算法修改了AdaGrad的梯度积累为指数加权的移动平均,使得其在非凸设定下效果更好。各种优化器用的是不同的优化算法(如Mmentum、SGD、Adam等),本质上都是梯度下降算法的拓展。下图通过可视化对各种优化器进行了对比分析,机器学习从目标学习到最优的过程,有不同的学习路径,由于Momentum考虑了上一步的学习(learning_rate),走的路径会很长;GradientDescent的学习时间会非常慢。建议如下:
如果您是初学者,建议使用GradientDescentOptimizer即可,如果您有一定的基础,可以考虑下MomentumOptimizer、AdamOptimizer两个常用的优化器,高阶的话,可以尝试学习RMSPropOptimizer优化器。总之,您最好结合具体的研究问题,选择适当的优化器。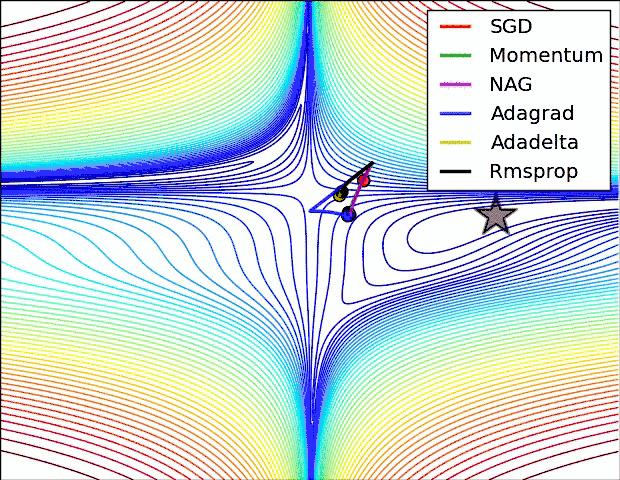
6.卷积层
为什么会提出卷积层呢?因为全连接层存在一个核心痛点:
图片参数太多,比如1000*1000的图片,加一个隐藏层,隐藏层节点同输入维数,全连接的参数是10^12,根本训练不过来这么多参数。利器一:局部感知野
提出了一个卷积核的概念,局部感知信息。
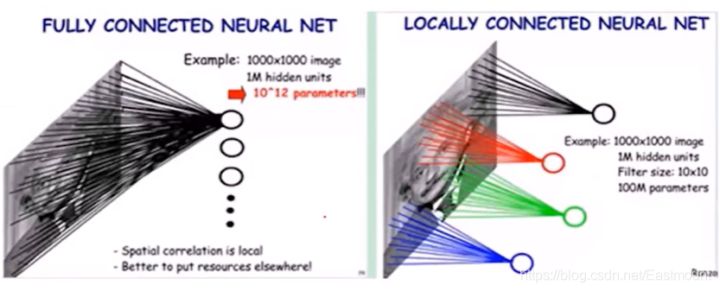
利器二:参数共享从图像的左上角按照3x3扫描至右下角,获得如右图所示的结果,通过卷积共享减少了参数个数。注意,这里的卷积核是如下:
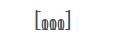
当前扫描的区域为如下,最终计算结果为2。
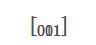
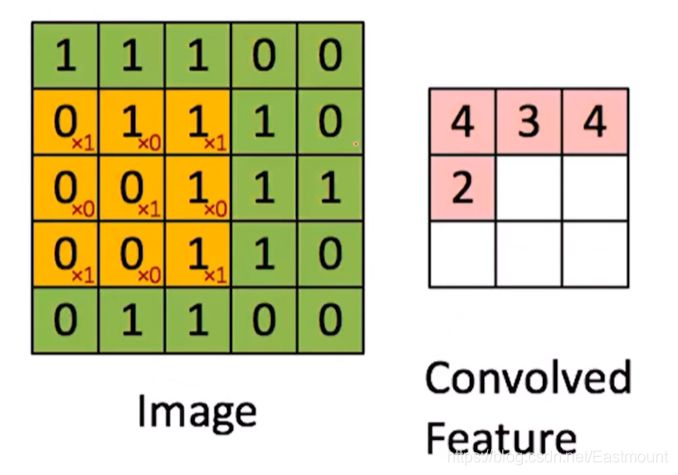
卷积层的核心知识点如下:
卷积核数目卷积核大小:如上面3x3卷积核卷积核数目卷积核步长:上面的步长是1,同样可以调格激活函数Padding:比如上图需要输出5x5的结果图,我们需要对其外圆补零是否使用偏置学习率初始化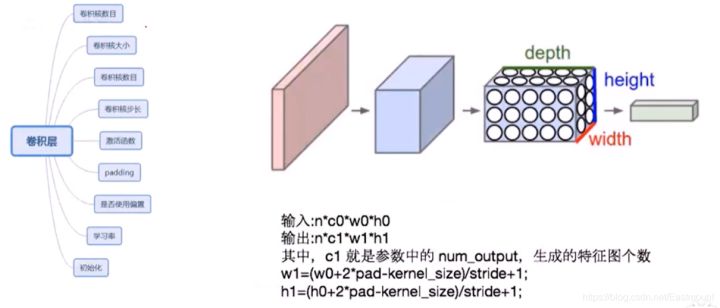
下图展示了五层卷积层,每层输出的内容。它从最初简单的图形学习到后续的复杂图形。

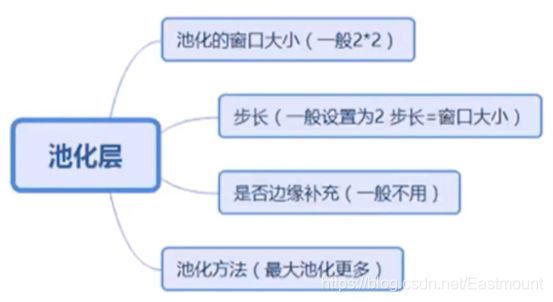
7.池化层
池化层主要解决的问题是:
使特征图变小,简化网络;特征压缩,提取主要特征常用池化层包括:
最大池化:比如从左上角红色区域中选择最大的6,接着是8、3、4平均池化:选择平均值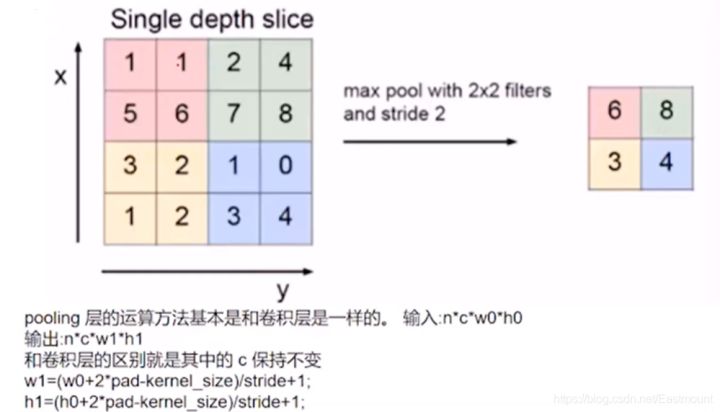
基本知识点如下图所示:
8.图像问题基本思路
此时,我们通过介绍的全连接层、卷积层、池化层,就能解决实际的问题。如下图所示:
输入层如NLP句子、句对,图像的像素矩阵,语音的音频信息表示成DNN:全连接+非线性(特征非线性融合)CNN:Conv1d、Conv2d、PoolingRNN:LSTM、GRU(选择记忆性)应用层分类、回归、序列预测、匹配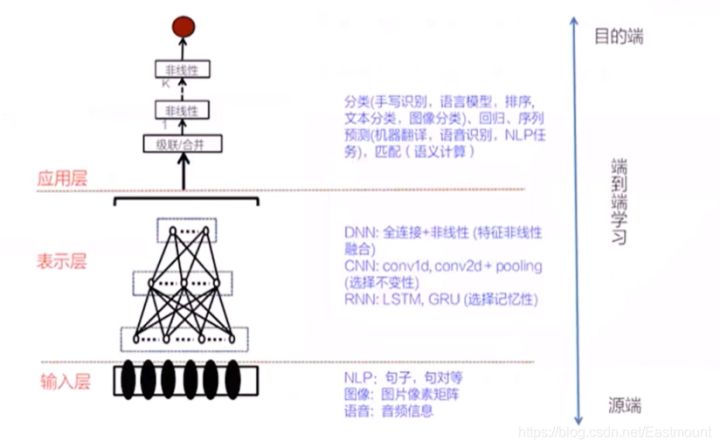
可以将图像问题基本思路简化为下图的模型。
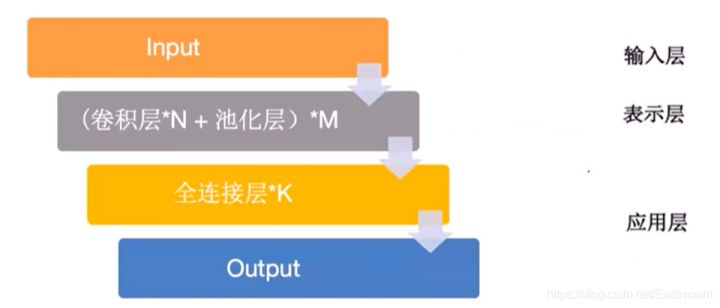
至此,预备知识介绍完毕!接下来我们进入GAN网络实战分析。
三.GAN网络实战分析
GANs(Generativeadversarial networks)对抗式生成网络
Generative:生成式模型Adversarial:采取对抗的策略Networks:网络1.GAN模型解析
首先,我们先说说GAN要做什么呢?
最开始在图(a)中我们生成绿线,即生成样本的概率分布,黑色的散点是真实样本的概率分布,这条蓝线是一个判决器,判断什么时候应该是真的或假的。我们第一件要做的事是把判决器判断准,如图(b)中蓝线,假设在0.5的位置下降,之前的认为是真实样本,之后的认为是假的样本。当它固定完成后,在图©中,生成器想办法去和真实数据作拟合,想办法去误导判决器。最终输出图(d),如果你真实的样本和生成的样本完全一致,分布完全一致,判决器就傻了,无法继续判断。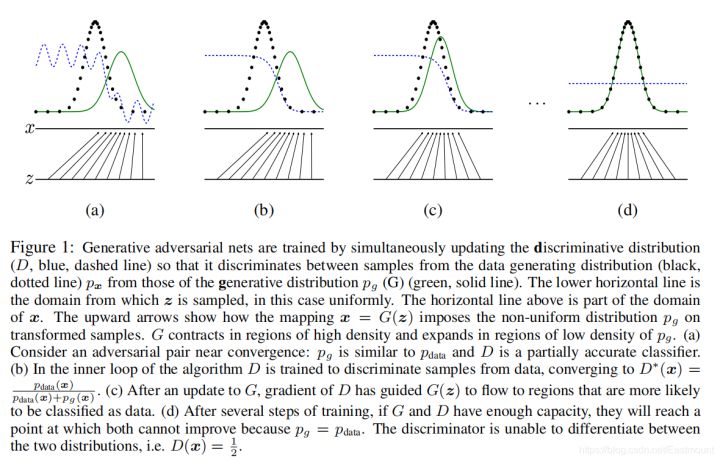
可能大家还比较蒙,下面我们再详细介绍一个思路。
生成器:学习真实样本以假乱真判别器:小孩通过学习成验钞机的水平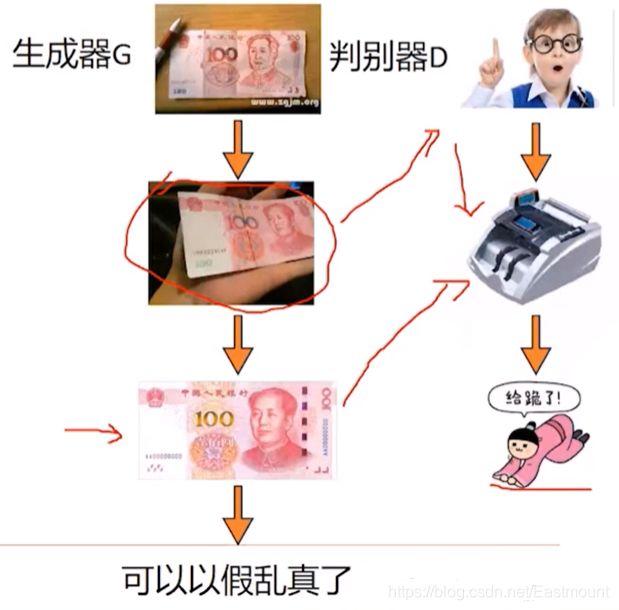
GAN的整体思路是一个生成器,一个判别器,并且GoodFellow论文证明了GAN全局最小点的充分必要条件是:生成器的概率分布和真实值的概率分布是一致的时候。
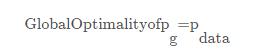
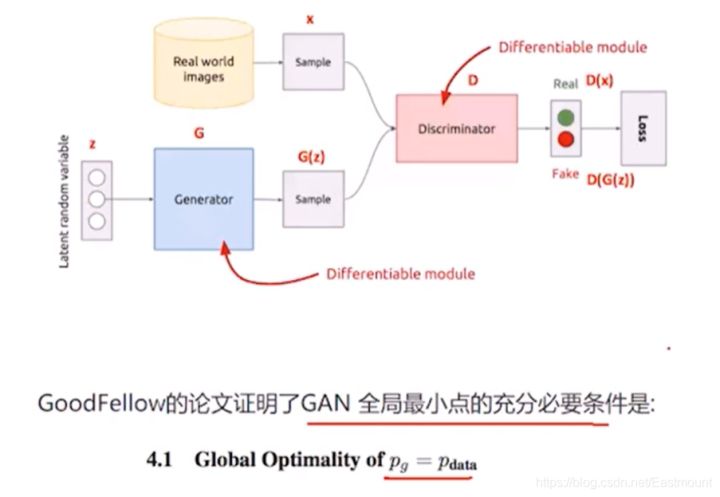
其次,GAN还需要分析哪些问题呢?
目标函数如何设定?如何生成图片?G生成器和D判决器应该如何设置?如何进行训练?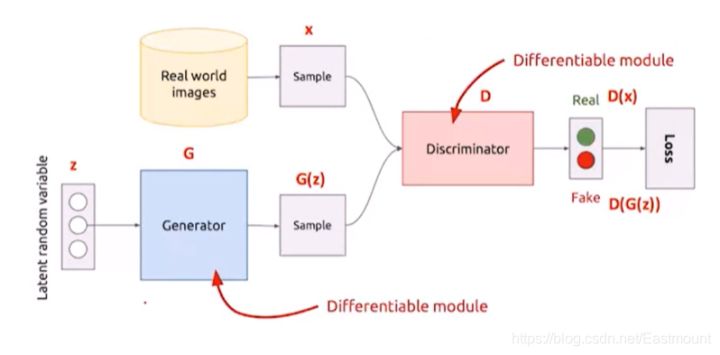
(1) 目标函数
该目标函数如下所示,其中:
max()式子是第一步,表示把生成器G固定,让判别器尽量区分真实样本和假样本,即希望生成器不动的情况下,判别器能将真实的样本和生成的样本区分开。min()式子是第二步,即整个式子。判别器D固定,通过调整生成器,希望判别器出现失误,尽可能不要让它区分开。这也是一个博弈的过程。
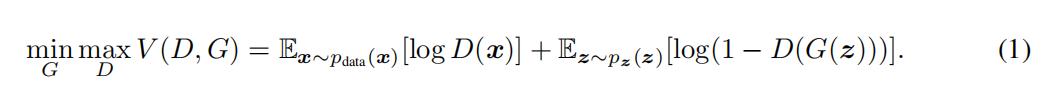
整个公式的具体含义如下:
式子由两项构成,x表示真实图片,z表示输入G网络的噪声,而G(z)表示G网络生成的图片。D(x)表示D网络判断真实图片是否真实的概率(因为x就是真实的,所以对于D来说,这个值越接近1越好)。D(G(z))是D网络判断G生成的图片是否真实的概率。G的目的:G应该希望自己生成的的图片越接近真实越好。D的目的:D的能力越强,D(x)应该越大,D(G(x))应该越小,这时V(D,G)会变大,因此式子对于D来说是求最大(max_D)。trick:为了前期加快训练,生成器的训练可以把log(1-D(G(z)))换成-log(D(G(z)))损失函数。接着我们回到大神的原论文,看看其算法(Algorithm 1)流程。
最外层是一个for循环,接着是k次for循环,中间迭代的是判决器。k次for循环结束之后,再迭代生成器。最后结束循环。
(2) GAN图片生成
接着我们介绍训练方案,通过GAN生成图片。
第一步(左图):希望判决器尽可能地分开真实数据和我生成的数据。那么,怎么实现呢?我的真实数据就是input1(Real World images),我生成的数据是input2(Generator)。input1的正常输出是1,input2的正常输出是0,对于一个判决器(Discriminator)而言,我希望它判决好,首先把生成器固定住(虚线T),然后生成一批样本和真实数据混合给判决器去判断。此时,经过训练的判决器变强,即固定生成器且训练判决器。第二步(右图):固定住判决器(虚线T),我想办法去混淆它,刚才经过训练的判决器很厉害,此时我们想办法调整生成器,从而混淆判别器,即通过固定判决器并调整生成器,使得最后的输出output让生成的数据也输出1(第一步为0)。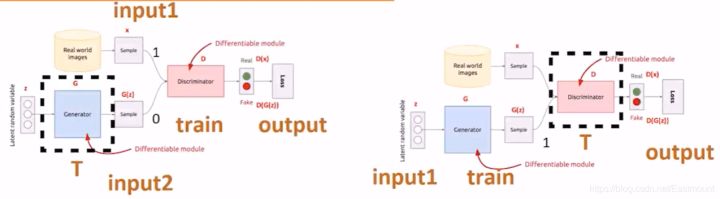
GAN的核心就是这些,再简单总结下,即:
步骤1是在生成器固定的时候,我让它产生一批样本,然后让判决器正确区分真实样本和生成样本。(生成器标签0、真实样本标签1)步骤2是固定判决器,通过调整生成器去尽可能的瞒混判决器,所以实际上此时训练的是生成器。(生成器的标签需要让判决器识别为1,即真实样本)其伪代码如下:
for 迭代 in range(迭代总数):\n for batch in range(batch_size):\n 新batch = input1的batch + input2的batch (batch加倍)\n for 轮数 in range(判别器中轮数):\n 步骤一 训练D\n 步骤二 训练G
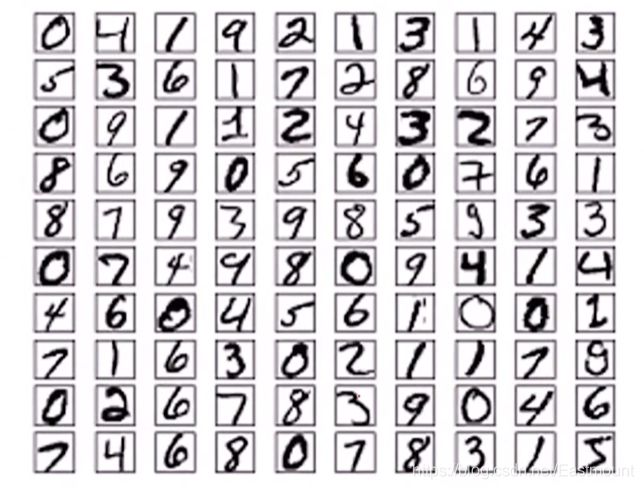
2.生成手写数字demo分析
接下来我们通过手写数字图像生成代码来加深读者的印象。这是一个比较经典的共有数据集,包括图像分类各种案例较多,这里我们主要是生成手写数字图像。
首先,我们看看生成器是如何生成一个图像(从噪音生成)?核心代码如下,它首先要随机生成一个噪音(noise),所有生成的图片都是靠噪音实现的。Keras参考代码:
(1) 生成器G生成器总共包括:
全连接层:输入100维,输出1024维全连接层:128x7x7表示图片128通道,大小7x7BatchNormalization:如果不加它DCGAN程序会奔溃UpSampling2D:对卷积结果进行上采样从而将特征图放大 14x14Conv2D:卷积操作像素尺度不变(same)UpSampling2D:生成28x28Conv2D:卷积操作Activation:激活函数tanh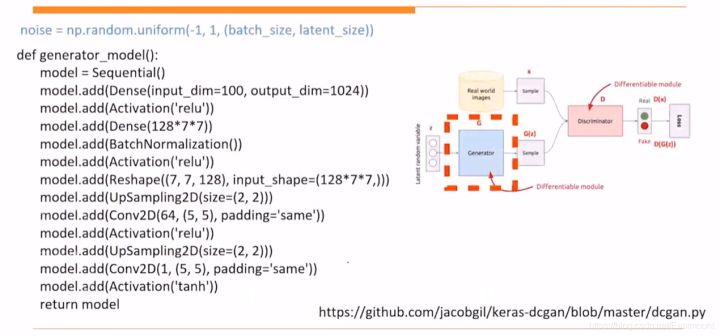
(2) 判别器D判别器就是做一个二分类的问题,要么真要么假。
Conv2D:卷积层MaxPooling2D:池化层Conv2D:卷积层MaxPooling2D:池化层Flatten:拉直一维Dense:全连接层Activation:sigmoid二分类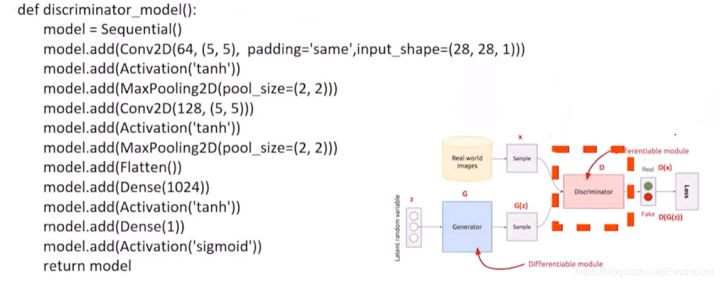
(3) 辅助函数如何把D固定去调整G的函数generator_containing_discriminator。
model.add(g):加载生成器Gd.trainable=False:判决器D固定combine_images函数实现合并图像的操作。

(4) GAN图片生成训练GAN核心流程包括:
load_data:载入图片d = discriminator_model:定义判别器Dg = generator_model:定义生成器Ggenerator_containing_discriminator:固定D调整GSGD、compile:定义参数、学习率for epoch in range、for index in rangeBATCHX = np.concatenate:图像数据和生成数据混合y = [1] x BATCH_SIZE + [0] x BTCH_SIZE:输出labeld_loss = d.train_on_batch(X,y):训练D判别器(步骤一)d.trainable = False:固定Dg_loss = d_on_g.train_on_batch(noise, [1]xBATCH_SIZE):训练G生成器(步骤二),混淆d.trainable = True:打开D重复操作保存参数和模型
(5) 生成模型训练好之后,我们想办法用GAN生成图片。
g = generator_model:定义生成器模型g.load_weights:载入训练好的生成器(generator)noise:随机产生噪声然后用G生成一幅图像,该图像就能欺骗判别器D
完整代码如下:
这段代码更像一个简单的GAN生成图片。
# -*- coding: utf-8 -*-\n\nCreated on 2021-03-19\n@author: xiuzhang Eastmount CSDN\n参考://p1-tt.byteimg.com/origin/tos-cn-i-qvj2lq49k0/351e481f69654fa3b0f6915316023818.jpg" style="width: 650px;">
Epoch is 0\nNumber of batches 468\nbatch 0 d_loss : 0.648902\nbatch 0 g_loss : 0.672132\nbatch 1 d_loss : 0.649307\n....\nbatch 466 g_loss : 1.305099\nbatch 467 d_loss : 0.375284\nbatch 467 g_loss : 1.298173\n\nEpoch is 1\nNumber of batches 468\nbatch 0 d_loss : 0.461435\nbatch 0 g_loss : 1.231795\nbatch 1 d_loss : 0.412679\n....

运行过程中会生成很多图像,随着训练次数增加图像会越来越清晰。

然后参数设置为“generate”,利用GAN最终生成图像,如下图所示。

3.其他常见GAN网络
(1) CGAN
首先,GAN如何输出指定类的图像呢?
CGAN出场。这里简单介绍下GAN和CGAN的区别:GAN只能判断生成的东西是真的或假的,如果想指定生成图像如1、2、3呢?GAN会先生成100张图像,然后从中去挑选出1、2、3,这确实不方便。
在2014年提出GAN时,CGAN也被提出来了。CGAN除了生成以外,还要把条件带出去,即带着我们要生成一个什么样的图条件去混淆,如下右图:噪声z向量+条件c向量去生成。
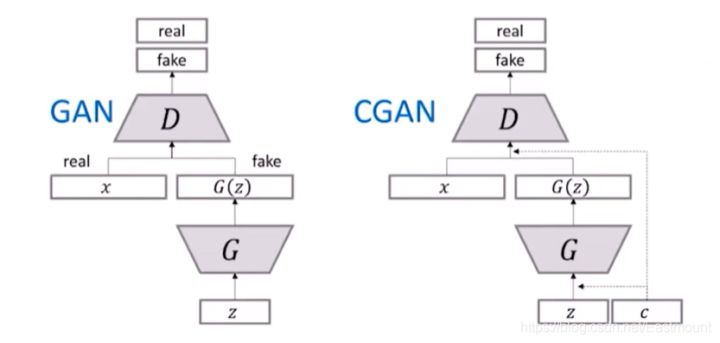
所以整套流程大体不变,接着我们看看公式,它在D(x|y)和G(z|y)中增加了y。其中,y不一定是指定类的输出,可以是一些条件。

(2) DCGAN
DCGAN(Deep Convolutional Generative Adversarial Networks)
卷积神经网络和对抗神经网络结合起来的一篇经典论文,核心要素是:在不改变GAN原理的情况下提出一些有助于增强稳定性的tricks。注意,这一点很重要。因为GAN训练时并没有想象的稳定,生成器最后经常产生无意义的输出或奔溃,但是DCGAN按照tricks能生成较好的图像。
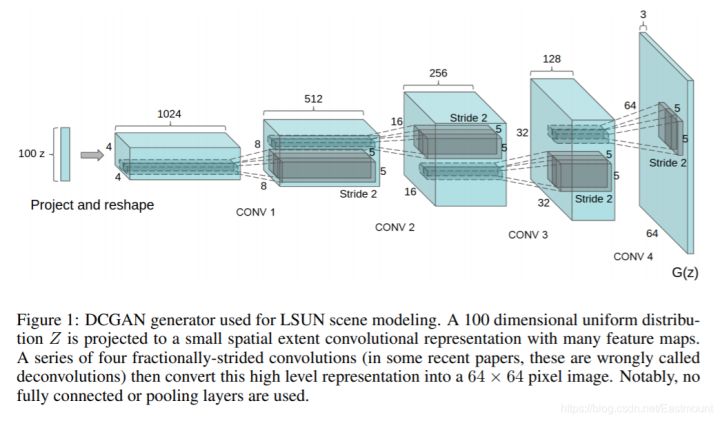
DCGAN论文使用的tricks包括:
所有pooling都用strided convolutions代替,pooling的下采样是损失信息的,strided convolutions可以让模型自己学习损失的信息生成器G和判别器D都要用BN层(解决过拟合)把全连接层去掉,用全卷积层代替生成器除了输出层,激活函数统一使用ReLU,输出层用Tanh判别器所有层的激活函数统一都是LeakyReLU
(3) ACGAN
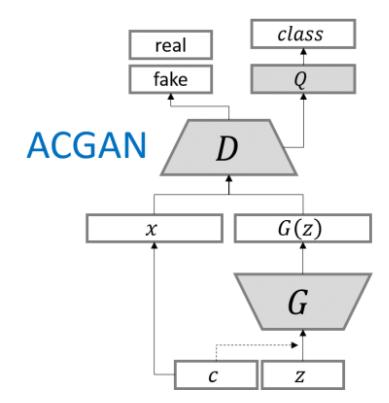
ACGAN(既能生成图像又能进行分类)Conditional Image Synthesis with Auxiliary Classifier GANs,该判别器不仅要判断是真(real)或假(fake),还要判断其属于哪一类。
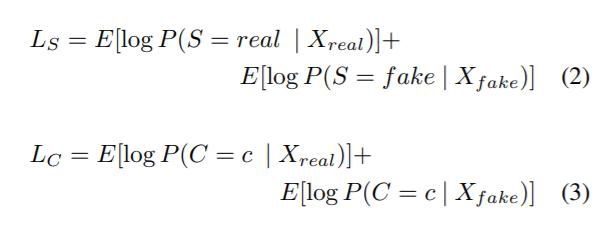
(4) infoGAN
InfoGAN:Interpretable Representation Learning by Information Maximizing Generative Adversarial Networks。这个号称是OpenAI在2016年的五大突破之一。
D网络的输入只有x,不加cQ网络和D网络共享同一个网络,只是到最后一层独立输出G(z)的输出和条件c区别大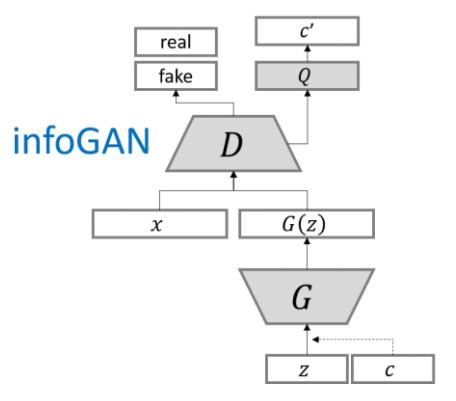
其理论如下:
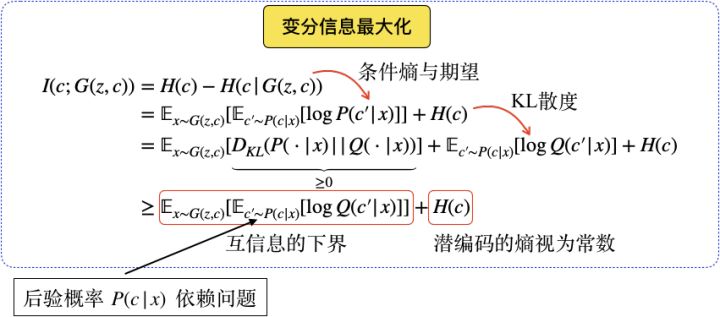
整个网络的训练在原目标函数的基础上,增加互信息下界L(G,Q),因此InfoGAN的目标函数最终表示为:
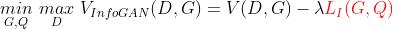
实验结果如下图所示:

(5) LAPGAN
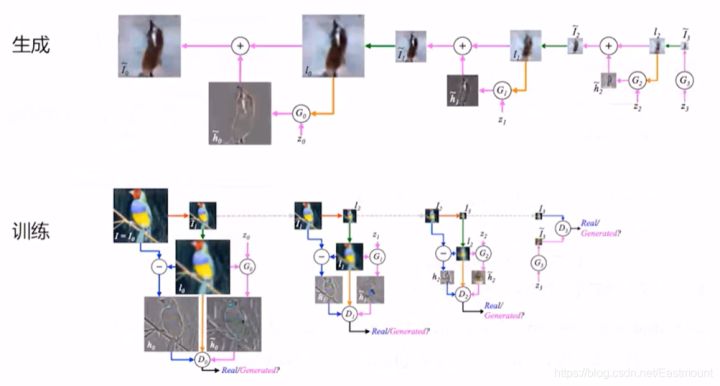
下面介绍一个比较有趣的网络拉普拉斯GAN。我们的目标是如何通过噪音生成一张图片,噪声本身生成图片比较困难,不可控量太多,所以我们逐层生成(生成从右往左看)。
首先用噪声去生成一个小的图片,分辨率极低,我们对其拉伸。拉伸之后,想办法通过之前训练好的GAN网络生成一个它的残差。残差和拉伸图相加就生成一张更大的图片,以此类推,拉普拉斯生成一张大图。那么,如何训练呢?对原来这个大图的鸟进行压缩,再生成一张图去判别,依次逐层训练即可。
(6) EBGAN
再来看一个EBGAN(Energy-based GAN),它抛弃了之前说的对和错的概念。它增加了一个叫能量的东西,经过自动编码器Enc(中间提取特征)和Dec解码器(输出),它希望生成一个跟真实图片的能量尽可能小,跟假的图片能量更大。
《Energy-based Generative Adversarial Network》Junbo Zhao, arXiv:1609.03126v2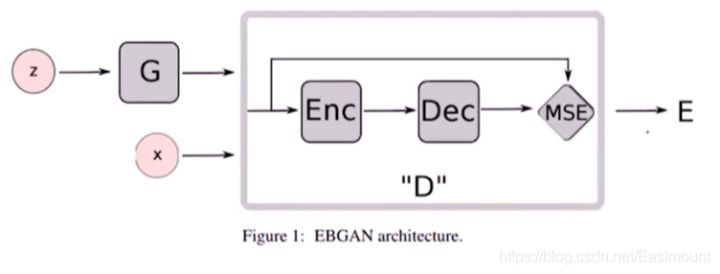
其生成器和判别器的损失函数计算公式如下(分段函数):
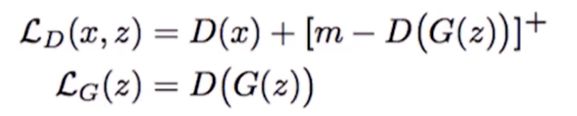
下图展示了GAN、EBGAN、EBGAN-PT模型生成的图像。

4.GAN改进策略
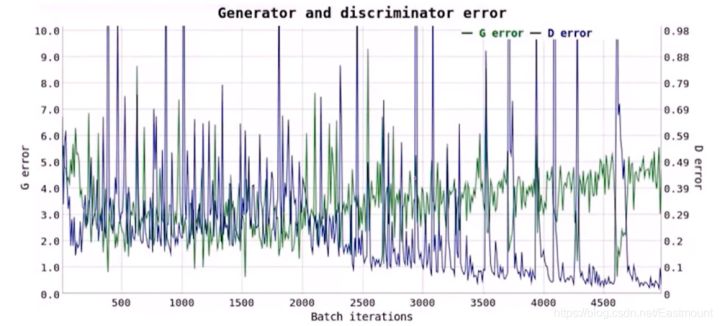
你以为解决了所有问题了吗?too young.如下图所示误差,我们无法判断GAN训练的好坏。
GAN需要重视:稳定(训练不奔)、多样性(各种样本)、清晰度(质量好),现在很多工作也是解决这三个问题。
G、D迭代的方式能达到全局最优解吗?大部分情况是局部最优解。不一定收敛,学习率不能高,G、D要共同成长,不能其中一个成长的过快– 判别器训练得太好,生成器梯度消失,生成器loss降不下去– 判别器训练得不好,生成器梯度不准,四处乱跑奔溃的问题,通俗说G找到D的漏洞,每次都生成一样的骗D无需预先建模,模型过于自由,不可控为什么GAN存在这些问题,这是因为GAN原论文将GAN目标转换成了KL散度的问题,KL散度就是存在这些坑。

最终导致偏向于生成“稳妥”的样本,如下图所示,目标target是均匀分布的,但最终生成偏稳妥的样本。
“生成器没能生成真实的样本” 惩罚小“生成器生成不真实的样本” 惩罚大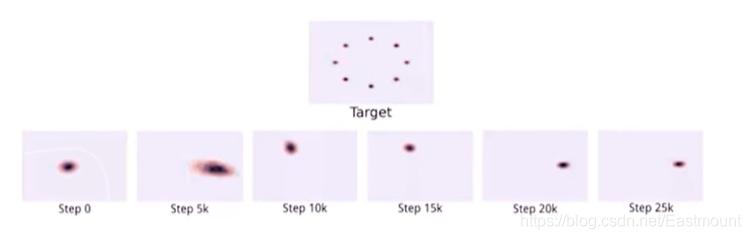
那么,有没有解决方法呢?WGAN(Wasserstein GAN)在2017年被提出,也算是GAN中里程碑式的论文,它从原理上解决了GAN的问题。具体思路为:
判别器最后一层去掉sigmoid生成器和判别器的loss不取log每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定的常数c不要用基于动量的优化算法(包括Momentum和Adam),推荐使用RMSProp、SGD用Wasserstein距离代替KL散度,训练网络稳定性大大增强,不用拘泥DCGAN的那些策略(tricks)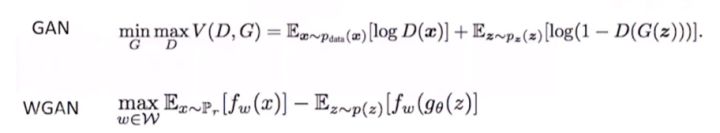
后续接着改进,提出了WGAN-GP(WGAN with gradient penalty),不截断,只对梯度增加惩罚项生成质量更高的图像。它一度被称为“state of the art”。

接下来,做GAN的就会出来反驳“谁说GAN就不如WGAN,我们加上Gradient Penalty,大家效果都差不多”。
//p1-tt.byteimg.com/origin/tos-cn-i-qvj2lq49k0/df6735a20d024dd79e290a7e7114de0d.jpg" style="width: 650px;">效果如下图所示:

《Google Brain: Are GANs Created Equal? A Large-Scale Study》 这篇论文详细对比了各GAN模型点心LOSS优化变种。

这篇文章比较的结论为:特定的数据集说特定的事情,没有哪一种碾压其他。好的算法还得看成本,时间短的效果某家强,但训练时间长了,反倒会变差。根据评价标准的不同,场景的不同,效果差的算法也可以逆袭。工业界更看重稳定性,比如WGAN。
参考知乎苏剑林老师的回答首先,从理论完备的角度来看,原始的GAN(SGAN)就是一个完整的GAN框架,只不过它可能存在梯度消失的风险。而论文比较的是 “大家都能稳定训练到收敛的情况下,谁的效果更好” 的问题,这答案是显然易见的:不管是SGAN还是WGAN,大家都是理论完备的,只是从不同角度看待概率分布的问题而已,所以效果差不多是正常的。甚至可以说,SGAN的理论更完备一些(因为WGAN需要L约束,而目前L约束的各种加法都有各自的缺点),所以通常来说SGAN的效果还比WGAN效果好一些。那么WGAN它们的贡献是什么呢?WGAN的特点就是基本上都能 “稳定训练到收敛”,而SGAN相对而言崩溃的概率更大。所以,如果在“大家都能稳定训练到收敛”的前提下比较效果,那对于WGAN这些模型本来就很不公平的,因为它们都是致力于怎么才能“稳定训练到收敛”,而这篇论文直接将它作为大前提,直接抹杀了WGAN所作的贡献了。
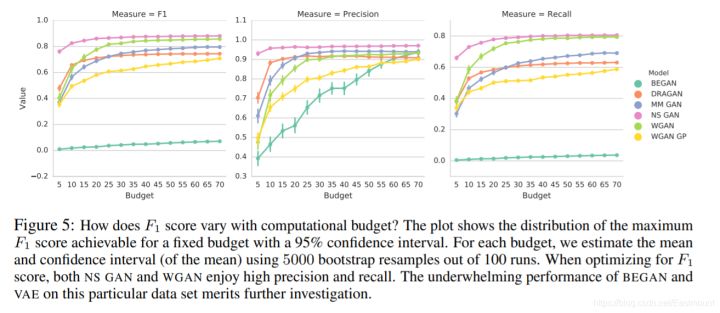
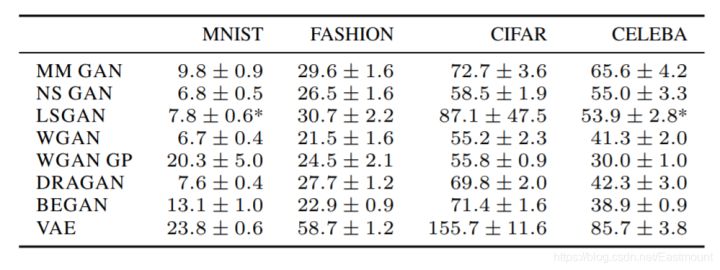
四.总结
个人感觉GAN有一部分很大的应用是在做强化学习,同时在推荐领域、对抗样本、安全领域均有应用,希望随着作者深入能分享更多的实战性GAN论文。比如如果图片被修改,GAN能不能第一次时间反馈出来或优化判决器。最后给出各类GAN模型对比图。
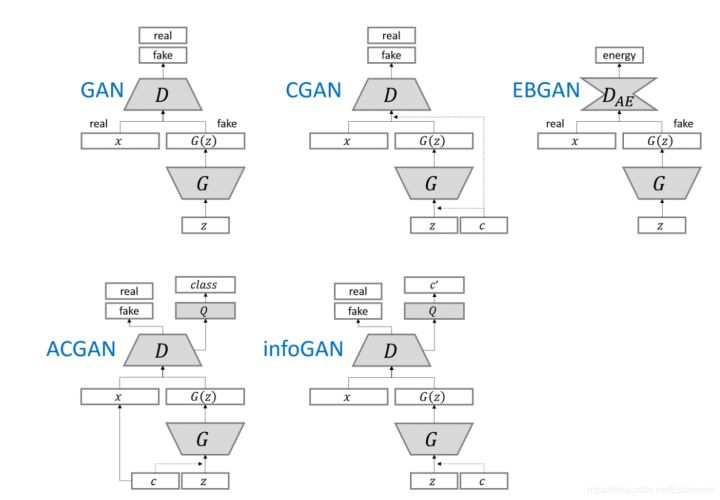
参考文献:
https://www.bilibili.com/video/BV1ht411c79khttps://arxiv.org/abs/1406.2661https://www.cntofu.com/book/85/dl/gan/gan.mdhttps://github.com/hindupuravinash/the-gan-zoohttps://arxiv.org/pdf/1701.00160.pdfhttps://link.springer.com/chapter/10.1007/978-3-319-10593-2_13https://zhuanlan.zhihu.com/p/76520991http://cn.arxiv.org/pdf/1711.09020.pdfhttps://www.sohu.com/a/121189842_465975https://www.jianshu.com/p/88bb976ccbd9https://zhuanlan.zhihu.com/p/23270674ttps://http://blog.csdn.net/weixin_40170902/article/details/80092628https://www.jiqizhixin.com/articles/2016-11-21-4https://github.com/jacobgil/keras-dcgan/blob/master/dcgan.pyhttps://arxiv.org/abs/1511.06434https://arxiv.org/pdf/1511.06434.pdfhttps://blog.csdn.net/weixin_41697507/article/details/87900133https://zhuanlan.zhihu.com/p/91592775https://liuxiaofei.com.cn/blog/acgan与cgan的区别/https://arxiv.org/abs/1606.03657https://blog.csdn.net/sdnuwjw/article/details/83614977《Energy-based Generative Adversarial Network》Junbo Zhao, arXiv:1609.03126v2https://www.jiqizhixin.com/articles/2017-03-27-4https://zhuanlan.zhihu.com/p/25071913https://arxiv.org/pdf/1705.07215.pdfhttps://arxiv.org/pdf/1706.08500.pdfhttps://arxiv.org/pdf/1711.10337.pdfhttps://www.zhihu.com/question/263383926版权声明:CosMeDna所有作品(图文、音视频)均由用户自行上传分享,仅供网友学习交流。若您的权利被侵害,请联系删除!
本文链接://www.cosmedna.com/article/778363942.html