GAN是一个非常巧妙并且非常有用的模型。当有大量关于 GAN 的论文时,但是你会发现这些论文通常很难理解,你可能会想要一些对初学者更友好的东西。所以本文的对非传统机器学习人员来说,是我能想到的最好的例子。
什么是 GAN?
GANs 或 Generative Adversarial Networks 是一类机器学习技术,由两个网络组成,相互进行对抗性学习。
这一切都是为了创造。 音乐? 绘画? 不存在的人的可怕逼真的照片? 大声笑等等。
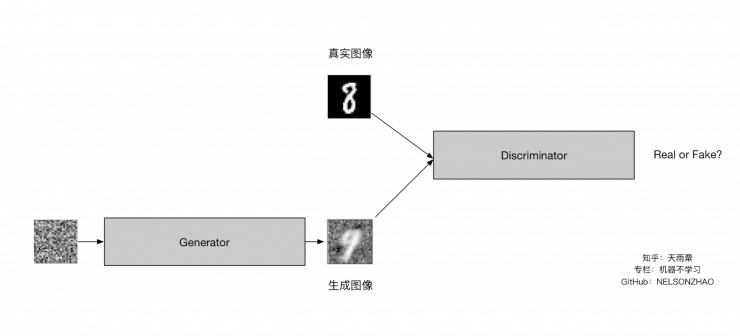
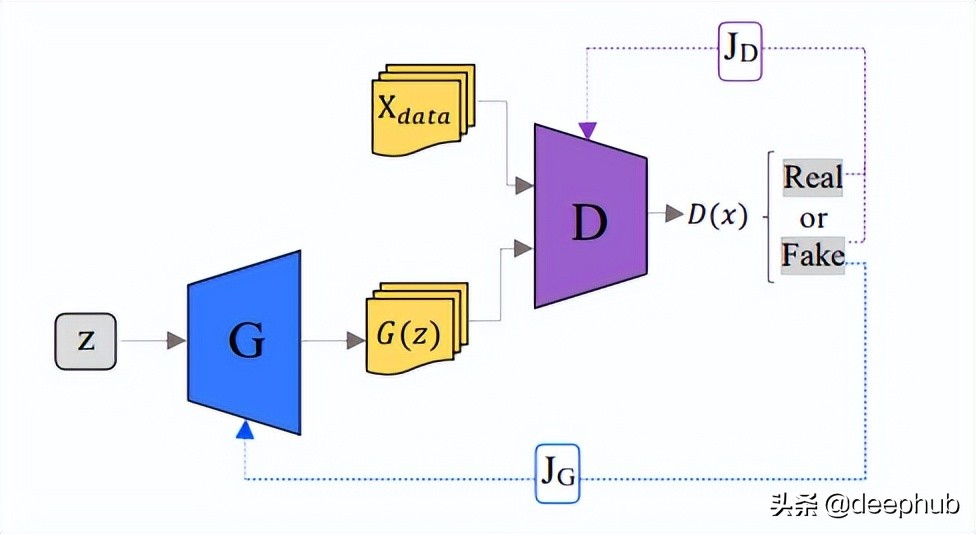
GAN中的网络一个被称为 Generator,可以将其视为一种伪造者,第二个称为 Discriminator,可以将其视为侦探。 生成器的主要目标是生成逼真的图像,而鉴别器则试图区分真假图像。
假设生成器正在尝试创建猫的图片,而鉴别器必须确定它是真正的猫还是 AI 生成的。
它是如何工作的?
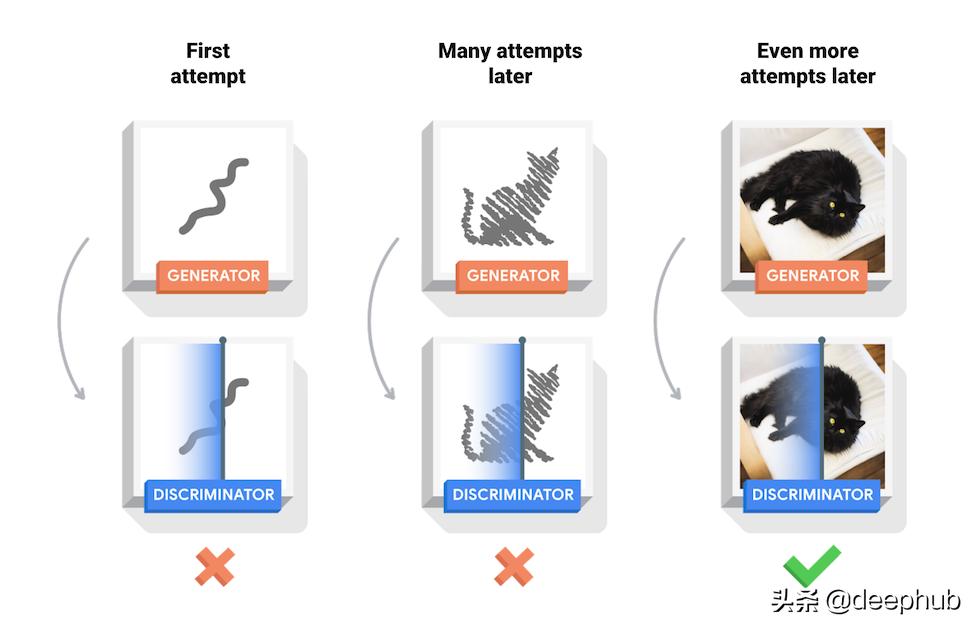
判别器和生成器都在开始时随机初始化并同时进行训练。 开始时生成器只产生一些随机噪声,经过训练在创建逼真的图像方面越来越好,而鉴别器在区分它们方面越来越好。 在模型达到平衡后,鉴别器就无法区分真实图像和假图像。 在推理阶段,我们不再需要判别器,只是用生成器进行工作。
生成器试图最小化以下函数,而鉴别器试图最大化它:
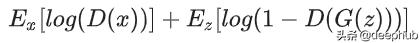
损失函数,D(y) 是判别器对真实数据实例 y 为真实的概率的估计。 G(z) 是给定噪声 z 时生成器的输出。 D(G(z)) 是鉴别器对假实例是真实的概率的估计。
简单来说,生成器目的是希望欺骗鉴别器让其相信输出是真实的,这意味着生成器的权重经过优化,以最大限度地提高此处任何假图像输出属于真实数据集的概率,而判别器应该最小化相同的概率。 生成器不能直接影响函数中的 log(D(x)) 项,因此对于生成器来说最小化损失相当于最小化 log(1-D(G(z)))。
生成模型一般基于马尔可夫链、最大似然估计(maximum likelihood estimation, MLE)和近似推理,其似然值在区间[0,1]内。
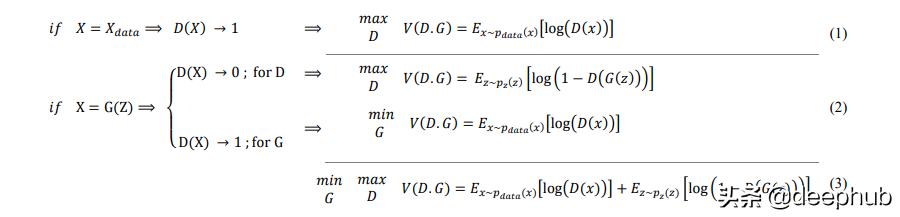
在均衡时D输出1/2,因为鉴别器不能区分生成的虚假数据和真实数据。
在无监督学习(数据没有标签)中,我们选择G生成的数据有0标签表示false(不管discriminator返回什么),真正的学习数据有1标签表示true。所以GAN的损失函数是下面这样的:
# Wasserstein losses from `Wasserstein GAN` (//p1-tt.byteimg.com/origin/tos-cn-i-qvj2lq49k0/37cf4c51723e4d2e90686f94be6a9489.jpg" style="width: 650px;">
GAN 与以前的生成方法(例如变分自动编码器或受限玻尔兹曼机)相比,已经显示出令人印象深刻的改进。 GAN在计算机视觉、信号处理、图像合成和编辑语音处理等各个领域已经有很多应用的例子,例如文本到图像的合成、图像到图像的翻译以及许多潜在的医学应用。
正因为如此,所以GAN也出现了很多变体,例如下图是 CycleGAN 做的一些很酷的事情

最后,如果你对GAN比较感兴趣,这里有个项目使用Pytorch实现了30多个GAN的经典论文,有兴趣的可以看看:
https://github.com/eriklindernoren/PyTorch-GAN
作者:Simran Sachdeva
版权声明:CosMeDna所有作品(图文、音视频)均由用户自行上传分享,仅供网友学习交流。若您的权利被侵害,请联系删除!
本文链接://www.cosmedna.com/article/611232587.html